InfoSec Compliance & AI Governance For over 20 years, DISC InfoSec has been a trusted voice for cybersecurity professionals—sharing practical insights, compliance strategies, and AI governance guidance to help you stay informed, connected, and secure in a rapidly evolving landscape.
Corporate visibility has become a business requirement rather than a marketing choice. Organizations publish employee profiles, leadership pages, technical blogs, social links, and recruiting content to build trust, attract talent, and improve customer confidence. However, every piece of public information expands the organization’s attack surface and creates intelligence opportunities for adversaries. The challenge is no longer whether to be visible, but how to operate securely while visible.
Security risks from corporate visibility are primarily reconnaissance-driven. Public information allows threat actors to identify key employees, map reporting structures, discover technology stacks, and understand operational processes before ever touching the network perimeter. Modern attacks increasingly target people and workflows rather than infrastructure vulnerabilities, making visibility management a core risk management function rather than just a branding consideration.
Corporate websites typically expose much more than organizations realize. Common examples include employee names, job titles, leadership bios, headshots, email address patterns, social media links, customer references, technology disclosures in job postings, project announcements, and partner ecosystems. Even seemingly harmless details such as organizational charts or department structures help attackers prioritize targets and craft convincing attack paths. Exposure becomes particularly problematic when public data can be correlated with breached credential repositories or social media activity.
This information becomes weaponized through open-source intelligence (OSINT) aggregation. Attackers combine public corporate data with social media, breach datasets, and AI-assisted analysis to create personalized phishing campaigns, helpdesk impersonation attempts, credential attacks, and business email compromise scenarios. The effectiveness comes from context: an email referencing a real manager, recent project, conference appearance, or customer relationship appears legitimate because the attacker already understands the organization. Personalized phishing and social engineering campaigns consistently outperform generic attacks because they exploit trust rather than technical weaknesses.
The rise of generative AI significantly accelerates this process. What previously required days or weeks of manual reconnaissance can now be automated in hours. AI systems can scrape websites, correlate identities, summarize relationships, generate targeted phishing content, and even imitate communication styles. This lowers attacker costs while increasing scale, meaning organizations should assume adversaries can rapidly build highly accurate organizational profiles from publicly available information.
The 2023 attack against MGM Resorts International demonstrates how corporate visibility intersects with operational failure. Threat actors associated with Scattered Spider reportedly used publicly available employee information and social engineering techniques to impersonate staff members during helpdesk interactions. By manipulating identity verification processes, attackers gained elevated access that eventually disrupted casino operations, digital services, and hotel operations, creating an estimated $100 million business impact. The attack highlighted that the primary weakness was not public information itself, but weak verification controls around sensitive processes.
The lesson from MGM is that identity assurance matters more than secrecy. Many security practitioners and incident observers noted that helpdesk workflows, MFA recovery procedures, and privileged account processes became the real attack surface. Attackers exploited human workflows because those controls failed under realistic social engineering pressure. Organizations often invest heavily in technology stacks while underinvesting in identity proofing, helpdesk security, and process resilience.
Operating securely when visibility is unavoidable requires layered controls. Organizations should assume attackers already possess employee names, reporting structures, and technology information. Recommended controls include phishing-resistant MFA, stronger helpdesk identity verification, out-of-band approval processes, role-based exposure reviews, periodic OSINT assessments, monitoring for credential exposure, and security awareness programs focused specifically on personalized social engineering. Security programs should shift from “prevent exposure” to “operate securely despite exposure.”
My perspective as a security risk professional is that corporate risk in the AI era is shifting from perimeter defense toward identity, trust, and context protection. AI amplifies attacker capabilities by making reconnaissance, impersonation, and influence operations faster and cheaper. Organizations that still treat public visibility as a branding problem rather than a risk management problem are underestimating how quickly AI-enabled adversaries can build organizational intelligence. The future control objective is not reducing visibility to zero; it is building security architectures, governance processes, and human workflows that remain resilient when attackers already know who your people are, what technologies you use, and how your business operates.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
Most GRC material stays stuck at the policy and framework level. This book is one of the few that actually tries to push the discipline into something the industry has been struggling with for years: engineering governance, risk, and compliance as a system—not a documentation exercise.
GRC ENGINEERING FOR AWS: A Hands-On Guide to Governance, Risk and Compliance Engineering takes a practical angle on something most compliance teams talk about but rarely implement well: embedding controls directly into cloud infrastructure, particularly AWS environments, and treating compliance as an engineering output rather than a periodic audit artifact.
From a GRC and AI governance perspective, the real value here is not theory—it’s operational translation.
Why this matters for GRC professionals
Most organizations today are sitting on three disconnected layers:
Frameworks (ISO 27001, NIST 800-53, SOC 2)
Cloud control implementation (AWS services, IAM, logging, config rules)
This book is useful because it focuses on closing that gap—specifically in AWS environments where most modern systems actually run.
Practical usefulness in real environments
Where this stands out is in its emphasis on:
Turning compliance controls into repeatable engineering patterns
Mapping governance requirements into cloud-native enforcement mechanisms
Reducing reliance on manual evidence collection through automation and infrastructure-level telemetry
Supporting continuous compliance thinking instead of audit-cycle compliance
For GRC professionals, especially those moving into vCISO or cloud governance roles, this is a shift in mindset: you are no longer just mapping controls—you are designing systems that produce compliant behavior by default.
Where it fits (and where it doesn’t)
This is not a strategic governance textbook. It won’t replace ISO 27001 interpretation or risk methodology design.
But it is highly relevant if you are:
Operating in AWS-heavy environments
Trying to operationalize NIST or ISO controls in cloud-native ways
Building continuous control monitoring or assurance programs
Bridging GRC and DevOps conversations (where most programs fail)
Bottom line
This book is most valuable as a practical translation layer between GRC frameworks and cloud engineering reality. For teams stuck between compliance requirements and engineering execution, it helps move the conversation from “what must we comply with?” to “how do we build it so compliance is automatic?”
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
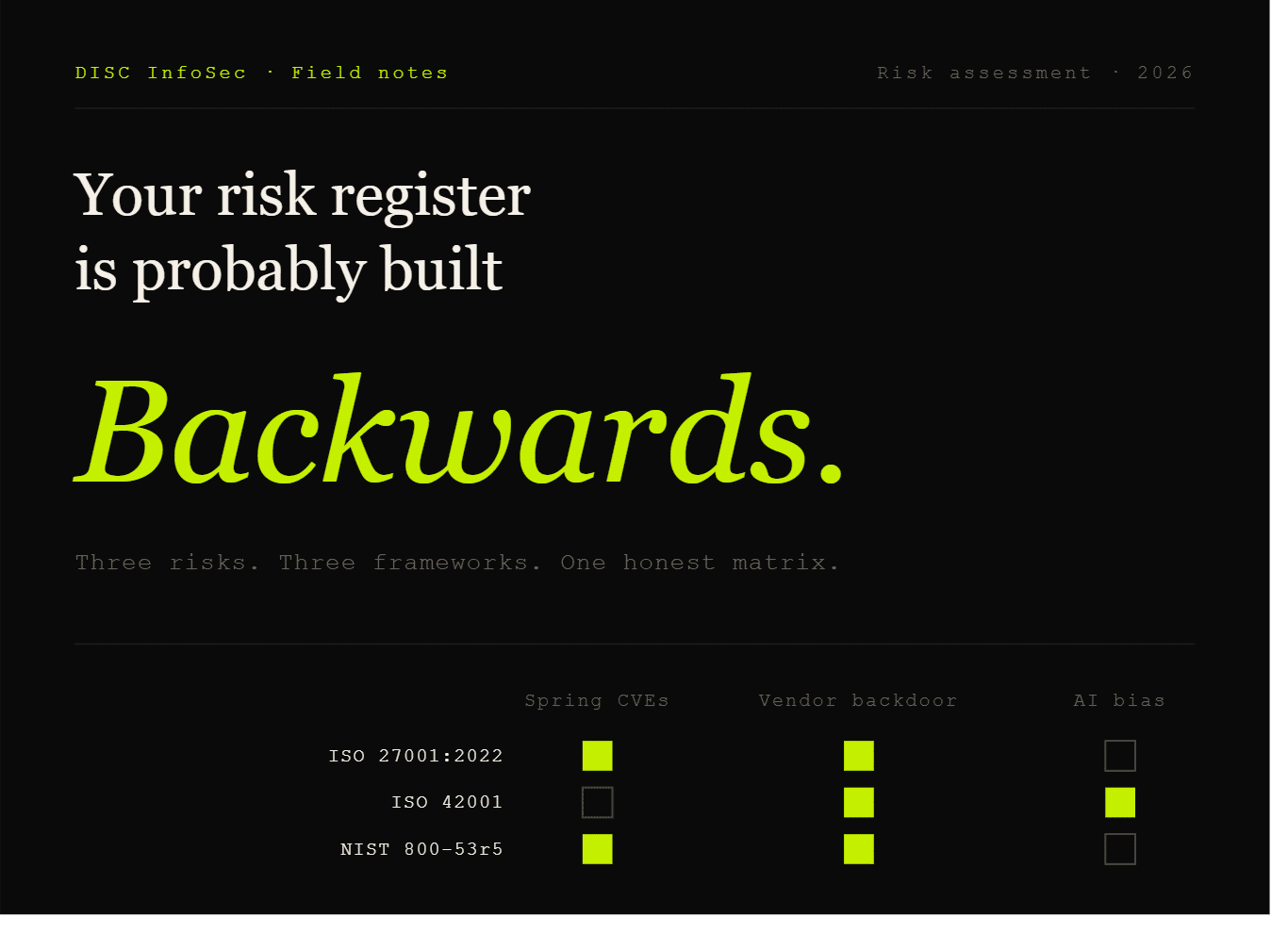
Four risks, three frameworks, and what mapping ISO 27001, ISO 42001, and NIST 800-53r5 actually looks like in practice.
Most risk registers are built backwards. Someone exports a control list from a framework, generates a row for each control, and reverse-engineers a “risk” to justify it. The result looks comprehensive and tells you almost nothing useful. Auditors recognize it on sight.
A working risk register starts from the other direction — from the business issue. What could materially hurt the company? What’s the mechanism? What controls actually move the needle? Then the framework mapping comes in, and only as a way to evidence that the controls you already need are also the ones the standards expect.
This post walks through four risks. Four come from a live register at a SaaS platform serving M&A and financial services clients — ISO 42001 & ISO 27001 certified. The fourth is the risk almost every SMB is currently running without measuring, and the one I expect to dominate AI-era incident reports for the next two years.
Risk 1 — Outdated Spring Framework and Spring Security
The business issue. The core application is running on Spring Framework 5.3.39 and Spring Security 5.8.16. Both are end-of-OSS-support. Both are missing fixes for high and critical CVEs that have been public for over a year. The framework underlies every authenticated request the platform serves, so the blast radius of any successful exploit is the entire customer base.
Contributing risk factors. Framework upgrades are the kind of work that gets deferred because nothing visibly breaks when you skip a quarter — until something does. Contributing factors typically include: engineering capacity prioritized toward customer-visible features, breaking-change risk in major Spring upgrades, dependency entanglement with libraries that pin to older Spring versions, and the absence of a configuration-as-code baseline that would make environment-by-environment upgrades safer to attempt.
How it relates across domains.
InfoSec: Direct exposure. Spring4Shell-class vulnerabilities and Spring Security authentication-bypass CVEs are not theoretical — they have working exploits, EDR signatures, and threat-actor playbooks.
Privacy: Indirect but real. An authentication bypass against a platform processing M&A diligence rooms means unauthorized access to highly sensitive personal and corporate data. GDPR Article 32 (security of processing) becomes the relevant hook.
Compliance: Indefensible at audit. “We are running a framework with known unpatched critical CVEs” is not a position you want to be in during a customer security questionnaire or an ISO 27001 surveillance audit.
AI governance: Tangential. But worth noting: if AI features depend on the same framework, the AI system’s confidentiality and integrity properties inherit the framework’s weaknesses. ISO 42001 expects you to know that.
Compensating controls already in place. CrowdStrike EDR, WAF, network segmentation, MFA, session controls. These reduce — but do not eliminate — exposure. They buy time. They are not a substitute for the upgrade.
Risk 2 — Hidden or Backdoor Functionality in Major Vendor Software
The business issue. Major vendor software in the stack (Apache Tomcat as one example, but the category is broader) could contain undocumented functionality — whether maliciously inserted, accidentally shipped, or buried in a dependency three layers deep. Recent industry events have made this category move from “theoretical supply-chain hand-wringing” to “the thing your insurance carrier asks about by name.”
Contributing risk factors. Vendor opacity. Lack of reproducible builds. Incomplete or absent SBOMs for transitive dependencies. The economic reality that even diligent vendor management cannot inspect code you do not have. The increasing sophistication of nation-state actors targeting widely deployed open-source components as a force multiplier.
How it relates across domains.
InfoSec: Detection is the only realistic primary control. You will not prevent this at the source — you will catch it through behavioral monitoring, anomaly detection, and network segmentation that limits what a compromised component can reach.
Privacy: If the compromised component handles personal data, you are looking at notification obligations under GDPR Article 33/34 and U.S. state breach laws. Processor relationships (Article 28) make this messier — you may be on the hook for a sub-processor’s exposure.
Compliance: Supply-chain assurance is one of the fastest-growing audit focus areas across ISO 27001:2022 (A.5.19–A.5.22), SOC 2, and regulator guidance. “We trusted the vendor” is not an acceptable answer anymore.
AI governance: If AI components or models come from third-party vendors — and most do, somewhere in the pipeline — supply-chain integrity extends to model weights, training datasets, and inference infrastructure. ISO 42001 A.10 (third-party and customer relationships) is the natural home for this.
Compensating controls already in place. Vendor management program, SBOM where available, CrowdStrike EDR for behavioral detection, network segmentation, Sumo Logic for anomaly detection, monitoring of third-party security research feeds.
Risk 3 — AI Feature Produces Misleading or Biased Output in Customer Use
The business issue. AI features in production — for example, financial, healthcare, or M&A document summarization and redaction recommendations — could produce outputs that are misleading, biased, or wrong in ways customers cannot easily detect. In a high-stakes diligence context, a confidently incorrect summary or a missed redaction is not a minor UX (User Experience) issue. It is a trust event, potentially a liability event, and depending on jurisdiction a regulatory event.
Contributing risk factors. Model limitations (every model has them; vendors do not always disclose them in operational terms). Training data quality and representativeness. Insufficient human-in-the-loop review for high-stakes outputs. Lack of structured output validation. The general gap between how AI systems are marketed and how they behave under tail-case inputs.
How it relates across domains.
InfoSec: Indirect. The risk is not confidentiality or integrity of the system — it is integrity of the output. This is the category where pure infosec frameworks run out of language and AI-specific governance has to take over.
Privacy: Direct under GDPR. Article 22 (automated decision-making), Articles 13–14 (transparency obligations), Article 5 (accuracy and fairness principles), and Article 35 (DPIA threshold) all engage when AI output materially affects an individual or a transaction.
Compliance: ISO 42001 is the primary frame. The 27001 hooks are thin and forcing them dilutes the analysis — bias and misleading output is genuinely a 42001-domain risk and should be scored there.
AI governance: This is the canonical ISO 42001 risk. Clause 8.3 (AI system impact assessment), Annex A.6.2.4 (system validation), A.7.4 (data quality), A.9.2 (operation), A.6.2.6 (system monitoring) — the entire 42001 spine engages here.
Compensating controls already in place. ISO 42001 AI management system controls, AI feature review and approval process, human-in-the-loop for high-stakes outputs, customer disclosure of AI use, model performance monitoring, output validation in QA, AI impact assessment process where threshold is met.
Risk 4 — Uncontrolled Data Exposure Through Shadow AI and Connected AI Tools
This is the most prolific AI security risk facing SMBs today, and it is almost universally underweighted on the registers I see. Most SMBs are running it actively, right now, without measuring it.
The business issue. Employees use consumer AI tools — ChatGPT free tier, Gemini, personal Claude accounts, AI meeting note-takers, AI browser extensions, AI plug-ins inside Slack and Notion and Chrome — to do real work. They paste customer data, source code, draft contracts, financial records, internal communications, and partner data into systems the company has no contractual relationship with, no DPA from, no visibility into, and often no acceptable use policy covering.
The connected AI tools half of this risk is the more dangerous one. A sanctioned AI meeting notetaker plugged into the corporate calendar. An AI sales assistant connected to the CRM. An AI coding agent with repository access. An AI feature that a SaaS vendor turned on in their latest release without prompting a fresh security review. Each of these has authenticated access to substantial corporate data. Each was typically procured department-by-department without going through vendor risk review, security review, or a DPIA. The aggregate data exposure is much larger than any individual decision-maker realized when they clicked “enable.”
Contributing risk factors. No AI acceptable use policy, or one that exists but is not enforced. No technical controls — no CASB, no DLP that recognizes AI endpoints, no browser-level AI gating. Consumer AI free tiers without enterprise-grade data protections (training opt-out, retention controls, audit logs). Procurement workflows that do not catch “this SaaS tool also has AI features now,” which by 2026 describes nearly every SaaS tool in the stack. BYOD environments where the company has no visibility into what is running. The general pace at which vendors are shipping AI features faster than security teams can review them.
How it relates across domains.
InfoSec: This is data exfiltration through user behavior rather than through exploit. The “attacker” is well-intentioned employees getting work done. That makes it the hardest category for traditional security tooling — there is no malware signature, no anomalous network destination if the AI tool runs in a sanctioned browser, no exfil pattern that EDR catches. Detection has to come from policy, awareness, DLP that understands AI endpoints, and vendor management.
Privacy: This is the heaviest privacy exposure on the register. Sending PII or customer data to an AI tool the company has no DPA with is a probable subprocessor violation under GDPR Article 28 and a likely CCPA issue. Purpose limitation (Article 5(1)(b)) and accuracy (Article 5(1)(d)) both engage. If the AI tool retains data for training, you have lost control of customer information you contractually promised to protect — and you may not be able to get it back.
Compliance: B2B SaaS customer contracts increasingly carry explicit subprocessor lists, data residency clauses, and prohibitions on sending customer data to AI training. Shadow AI usage breaks every one of those simultaneously. SOC 2 CC9.2 (vendor management) and ISO 27001 A.5.19–A.5.22 are the audit hooks. For regulated customers (financial services, healthcare), this can be a contract termination event.
AI governance: ISO 42001 covers this even when the AI is being used informally rather than deployed as a product. A.9.3 (responsible use) and A.5.2–A.5.5 (AI policy framework) apply to ad-hoc internal usage. This is exactly the gap that catches SMBs without an AI management system in place.
A note on the SMB profile specifically. Enterprises have legal, procurement, and security teams that can absorb some of this risk through process. SMBs typically do not. The 30-person SaaS company where everyone has admin on their own laptop and procures their own SaaS tools is the canonical Shadow AI environment. Most don’t know what data is being sent where, and most have no realistic path to find out without first putting policy and tooling in place. The good news: this is the risk where the early-stage investments — an AI AUP, vendor inventory, awareness training, browser-level controls — produce disproportionate residual-risk reduction.
Compensating controls in a mature program. AI acceptable use policy, AI vendor inventory, AI-aware DLP, browser-level controls or CASB enforcement on AI endpoints, awareness training that names specific tools and specific behaviors, procurement gates that flag AI features in new and renewing contracts, periodic spot-checks of connected AI integrations across the SaaS estate.
The Control Matrix
The table below maps each risk to the controls that actually do the work — not every control that could conceivably touch the risk, just the ones that move residual exposure. The NIST column is split: 800-53r5 for the technical and operational risks where it has strong native coverage, NIST AI RMF for the AI-specific risks where 800-53 underperforms.
A.10.2 (allocation of responsibilities), A.10.3 (suppliers) — plus B.8 processor controls where Organization’s acts as processor
800-53r5: SR-3 (supply chain controls and processes), SR-6 (supplier assessments and reviews), SR-11 (component authenticity), RA-5 (vulnerability scanning), SI-2 (flaw remediation), SI-4 (system monitoring), AU-6 (audit record review, analysis, and reporting)
AI feature produces misleading or biased output
A.5.34 (privacy and PII protection) — and intentionally light here; this is a 42001 risk
A.6.2.4 (system validation), A.6.2.5 (system requirements), A.6.2.6 (system monitoring), A.6.2.8 (system documentation), A.7.2 (data for AI systems), A.7.4 (data quality), A.7.5 (data provenance), A.8.2 (responsible AI), A.8.3 (AI system impact assessment), A.9.2 (responsible use), A.5.2–A.5.5 (AI policy and governance)
NIST AI RMF: GOVERN-3.2 (AI risk roles and responsibilities), MAP-2.3 (system capabilities and limitations characterized), MEASURE-2.11 (fairness and bias evaluation), MANAGE-4.1 (post-deployment monitoring) — paired with 800-53r5 SA-11, RA-3, PM-31 as proxy controls
Shadow AI / connected AI tool data exposure
A.5.10 (acceptable use of information), A.5.14 (information transfer), A.5.19–A.5.22 (supplier relationships, applied to AI vendors), A.6.3 (information security awareness, education, and training), A.8.3 (information access restriction), A.8.12 (data leakage prevention — legitimate use here), A.8.16 (monitoring activities), A.5.34 (privacy and PII protection)
A.5.2–A.5.5 (AI policy framework), A.6.1.2 (AI objectives — including unsanctioned use boundaries), A.9.2 (responsible use), A.9.3 (use of AI systems), A.10.4 (customers — for downstream data flow impact)
800-53r5: AC-20 (use of external information systems), AC-21 (information sharing), AT-2 (literacy training and awareness), PL-4 (rules of behavior), SC-7 (boundary protection), SI-4 (system monitoring), CA-9 (internal system connections). NIST AI RMF: GOVERN-3.2 (roles and responsibilities), MAP-4.1 (third-party AI considerations), MANAGE-3.1 (AI risks and benefits documented)
A few things worth noticing about this matrix.
First, the AI bias row is intentionally light on ISO 27001. Forcing A.8.12 (DLP) or similar onto an AI bias risk is the kind of stretch that auditors notice and that practitioners do to make registers look symmetrical. Different risks live in different frameworks for a reason.
Second, A.8.12 (DLP) finally finds a legitimate home in the Shadow AI row. That control was the wrong fit for AI output bias, but it is exactly right for AI input leakage. Same control number, completely different risk story — which is part of why control-first registers fail.
Third, the Shadow AI row pulls from all three frameworks at near-equal weight. It is simultaneously a supplier risk, an awareness risk, a boundary-protection risk, an AI-governance risk, and a privacy risk. That cross-cutting profile is part of why it is hard for any single team to own — and part of why it sits unaddressed on so many registers.
Fourth, the supply-chain row pulls A.5.23 (cloud services) and SR-11 (component authenticity) explicitly. These have moved from “nice to have” to “expected” in the last twelve months as the audit community has caught up to the reality of modern dependency graphs.
A Practitioner’s Perspective on Mapping Business Risks to Frameworks
Six things I’ve learned doing this work at the implementation end rather than the consulting-deck end.
Start from the risk, not the control. Every register I have inherited that started from a control list is unusable. The ones that started from “what could materially hurt the business” are the ones that survive contact with an auditor and with reality. Frameworks are evidence, not source material. Shadow AI is the cleanest illustration of this principle in the current threat landscape — start from controls and you map it to DLP and call it done. Start from the business issue and you discover it is a policy gap, a vendor management gap, a training gap, a technical controls gap, and a privacy gap simultaneously. The controls are the answer. They are not the question.
Resist the urge to map everything to everything. A clean register has some empty cells. An AI bias risk genuinely does not have strong ISO 27001 coverage, and pretending otherwise dilutes both the risk analysis and the framework. If a column is light, write that down. Auditors prefer honesty over symmetry.
Use the right framework for the risk. NIST 800-53r5 is excellent for infrastructure and operational controls and underperforms on AI-specific risks. NIST AI RMF is purpose-built for the AI risks and has no opinion about your patching cadence. ISO 27001:2022 and ISO 42001 are designed to interlock — let them. The temptation to force one framework to cover everything is the single most common mistake I see in mid-market registers.
Compensating controls are real, but they are not the destination. Every one of the risks above has compensating controls in place. CrowdStrike, WAFs, segmentation, monitoring, human review, awareness training. These reduce velocity and impact. They do not eliminate the underlying issue. A register that scores residual risk as “low” because compensating controls exist — without a plan to remediate the root cause — is telling you a story about itself, not about the risk.
Score the risk the SMB is actually running, not the one the framework imagines. Shadow AI is the canonical example. Most SMB registers either omit it entirely or score it at moderate residual on the strength of an AUP nobody enforces. The honest score reflects what would happen if a customer audited the actual data flows tomorrow. That is usually a different number — and the gap between the two numbers is the value the security function is failing to deliver.
The capability-governance gap is the real risk category. Every one of these four risks is a version of the same problem: technical capability has outrun the governance and operational practices needed to keep it safe. The Spring stack is more complex than the upgrade process can keep up with. The supply chain is deeper than the vendor management program can see. The AI feature is more capable than the output validation can verify. The AI tools employees use are more numerous and more powerful than any inventory the company maintains. The frameworks are useful because they force you to close that gap — not because the controls themselves are magic.
A risk register is a forcing function. It makes you write down what you know, what you do not know, and what you are doing about it. The frameworks are the language you write it in. The business issues are what you are writing about. Get that order right and the register starts doing real work. Get it wrong and you have a document that satisfies no one — not the auditor, not the board, not the engineers who are supposed to fix the problem.
Written from the implementation seat. If you are working through similar risks on your own register — especially Shadow AI, which most SMBs are running unmeasured — DISC InfoSec does this work for B2B SaaS and financial services organizations. vCISO, vCAIO, ISO 42001 and ISO 27001 implementation, AI governance. Reach out: hd@deurainfosec.com.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
Earning Cybersecurity Confidence in the Age of Agentic AI — A Practitioner’s Read
Hrvoje Englman, CISO at Span, used his keynote at the Span Cyber Security Arena to describe a defender’s job that has been rewritten in roughly twenty-four months. Engineering teams are now writing their own software with AI coding assistants, spinning up agents that act on their behalf, and assigning those agents the same access privileges their human creators hold. The boundary between “the user” and “the workload” has effectively collapsed. Identities are over-provisioned by default, and least privilege — long the textbook answer — remains, in his words, an aspiration that is difficult to operationalize once agents start spawning agents inside production.
A second-order risk lands on top of that identity sprawl. Englman described what he frames as an inverted bus-factor problem: an engineer automates a workflow with a handful of interacting agents, leaves the company, and the agents keep running with no documentation behind them. The traditional concern was the knowledge gap left by a departing expert. The new concern is the operational system that outlives the expert and continues making business decisions that nobody can fully explain or audit. From a governance standpoint, this is exactly the failure mode ISO/IEC 42001 was written to prevent — and exactly the one most organizations have no inventory for.
Where AI does deliver, Englman is concrete. Log triage that used to consume analyst hours can be compressed against hundreds of megabytes of data, with anomalies and pivot points surfaced in minutes. Policy drafting against internal context can collapse a three-day exercise into a single day, and that compounding time savings is real across a workforce. He treats these as defender leverage that is already shipping value, not vendor theater.
He is far less generous to the marketing around autonomous, AI-driven SOCs. The premise of defensive AI versus offensive AI with no humans in the loop does not survive contact with operational reality. Log ingestion is still the unglamorous bottleneck. Detection engineering still depends on analysts who can articulate why an alert fired and what business process it touches. Englman captured the failure mode plainly: “You get an alert, but your analyst doesn’t understand the alert. And you have two million alerts, and then what?” Autonomous containment also breaks down because the model has no concept of which service is load-bearing for revenue at 2 a.m. — that judgment escalates to humans during real incidents, and it should. He further notes that most large breaches still trace to phishing and credential theft, which means the nation-state framing in vendor decks is solving a smaller slice of the actual loss curve than it implies.
The threat model is sharper still for a security services provider. Span is both a target and a path to its customers, which inverts the calculus a typical end-user organization works with. A normal enterprise can absorb a breach, run the playbook, and recover. For a provider, the incident response itself becomes the product on display — the proof that controls existed, that the blast radius was contained, and that the same operational discipline sold to customers was applied to the provider’s own house. Reputation is the asset, and negligence ends the business. This is the lens every B2B SaaS or managed-services CISO should be borrowing.
On talent, Englman reframes the so-called shortage. Entry-level candidates are plentiful; what is genuinely scarce is the senior practitioner with five-plus years of operational depth, and that bench cannot be conjured through six-week certifications. He worries — correctly, in my view — that the rush to automate junior SOC work is dismantling the apprenticeship pipeline that produces those senior people in the first place. His bar for an analyst is whether they can explain what an alert means and how the triggering conditions came about. Anything short of that is a coin flip dressed up as triage, whether the coin is human or model.
Finally, he discards the piece of conventional wisdom most CISOs still recite reflexively. The line that “humans are the weakest link” is, he argues, lazy and a form of blame culture. The accountability sits with the security function to engineer environments where one bad click does not collapse the business. Brittle defenses that assume perfect human behavior are a design failure dressed up as user awareness.
My perspective — what the CISO is actually selling.
Englman’s interview is, underneath the headlines, a thesis about how to sell confidence in three directions at once: upward to the board, inward to employees, and outward to customers and vendors. None of those audiences are buying a SOC anymore — they are buying the operating discipline behind it. To the board, confidence comes from being able to show that AI is governed the same way any other production system is governed: a mapped inventory of agents and their identities, a documented owner for each one, evidence that controls were designed in rather than bolted on, and the candor to say which threats your stack actually addresses versus which ones are marketing. ISO 42001, NIST AI RMF, and the EU AI Act each give the CISO a defensible scaffold for that conversation; the failure mode is treating them as paperwork instead of as the board narrative they were designed to be. To employees, confidence comes from being an enabler rather than a blocker — codifying acceptable AI use, shipping sanctioned tools faster than Shadow AI can spread, and treating “the user clicked the link” as a signal to fix architecture, not to publish another phishing scorecard. To vendors and customers, confidence is demonstrated in how an incident is handled, not promised in how one is prevented; the playbook, the tabletop cadence, the third-party audit evidence, the time-to-disclose discipline — that is the product. In a market saturated with breach headlines and autonomous-SOC vaporware, the CISOs who win the trust trade are the ones who can prove governance maturity in plain language, name the limits of their tooling honestly, and let operational evidence — not vendor promises — carry the weight.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
As enterprise adoption of generative AI accelerates, the operational gap between “AI as productivity tool” and “AI as governed enterprise application” has widened. Anthropic has moved to close that gap by introducing 28 integrations with security and compliance tools that allow IT and security teams to manage Claude in the same way they manage other applications in their environments. The announcement reframes Claude from a standalone SaaS product into a workload that fits inside an organization’s existing control plane.
The technical foundation for this is the newly introduced Claude Compliance API. It is a REST API that gives enterprise IT and security teams programmatic access to Claude activity data, replacing manual exports and periodic reviews with real-time programmatic access to usage data and customer content, enabling continuous monitoring and automated policy enforcement. In other words, Anthropic is treating governance signals as first-class telemetry rather than as an after-the-fact audit artifact.
Two data domains are exposed through the API. The first covers conversation content from Claude Enterprise — chats, uploaded files, and projects — which organizations can pipe into their existing security, monitoring, and data loss prevention pipelines. This is the layer where sensitive data exposure, prompt-side leakage, and content-policy violations get detected.
The second domain covers activity events from Claude Enterprise and the Claude Platform, including user logins, administrative actions, and configuration changes. This is the audit-trail layer that satisfies access governance, change management, and forensic reconstruction requirements — the kind of evidence external auditors actually open tickets about.
The 28 launch partners span a broad swath of the enterprise security stack: DLP, SASE, data security, SIEM, security operations, identity management, eDiscovery, AI security posture management, and observability. The named providers include Cloudflare, Cribl, CrowdStrike, Cyera, Datadog, Forcepoint, Fortinet, Geordie AI, IBM Guardium, Microsoft Purview, Mimecast, Netskope, Okta, Palo Alto Networks, Proofpoint, Relativity, ReliaQuest, Rubrik, SailPoint, Smarsh, Snyk, Sumo Logic, Tenable, Theta Lake, Trellix, Varonis, Wiz, and Zscaler. The breadth signals that Anthropic is meeting enterprises wherever their existing investment already sits.
The promised user experience is deliberately undramatic. For organizations already running one of these platforms, enabling coverage over Claude usage involves connecting and configuring the Claude instance so the data flows into the same dashboards and alerting workflows used for everything else. That framing matters: governance friction is the single biggest reason shadow AI proliferates, and “it shows up in your existing SIEM” is a far more compelling story to a CISO than “stand up a parallel monitoring stack for AI.”
Taken together, the move positions Claude as governable infrastructure rather than an unmanaged endpoint. It directly addresses the most common objection raised in enterprise AI risk assessments — that AI usage is opaque, ungoverned, and lives outside the controls that already govern email, file shares, and SaaS. By exposing both content and activity telemetry through a documented API, Anthropic is essentially handing customers the evidence base required to demonstrate operational controls during audits.
My perspective: this is one of the more consequential governance announcements from a frontier lab to date, and it deserves attention from anyone implementing ISO 42001, NIST AI RMF, or the EU AI Act in practice. Most AI governance programs I see fail not at the policy layer but at the evidence layer — clauses A.6.2.6 (operation), A.6.2.8 (monitoring), and A.9 (performance evaluation) of ISO 42001 all require demonstrable, ongoing oversight of AI system use, and until now that evidence has typically been cobbled together from screenshot exports and vendor attestations. A Compliance API that streams content and activity data into Purview, Netskope, or Varonis converts those clauses from aspirational language into something an internal auditor can actually sample. It also collapses the artificial boundary between “AI governance” and “information security governance,” which is the right outcome — AI systems are information systems, and treating them as a separate compliance silo has always been a structural mistake.
That said, two cautions are worth flagging. First, the API gives you the capability to monitor; it does not give you the program. Without a defined AI acceptable use policy, a classified inventory of AI use cases, role-based access boundaries, and a triage workflow for what to do when DLP fires on a Claude conversation, the telemetry just becomes noise in another dashboard. Second, ingesting conversation content into DLP and eDiscovery tools creates new data-protection obligations of its own — privacy impact assessments, retention schedules, and access controls on the captured prompts and outputs themselves. Organizations should plan for the governance of the governance data before turning the firehose on. For practitioners building toward ISO 42001 certification or a Stage 2 audit, this announcement is the kind of vendor-provided control surface that materially shortens the path to demonstrable conformity — provided the management system around it is actually built.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
In today’s rapidly evolving business environment, Governance, Risk, and Compliance (GRC) can no longer operate as disconnected activities managed by separate teams and spreadsheets. Organizations facing cyber threats, AI risks, regulatory pressure, and operational complexity need a unified GRC operating model that connects governance, risk management, compliance, assurance, and technology into one coordinated discipline.
True GRC maturity comes from building a system where leadership oversight, accountability, controls, reporting, and automation work together to support better business decisions. Organizations that achieve this level of maturity move beyond “check-the-box compliance” and create resilient, measurable, and scalable governance programs.
1. Strategic Governance
Every mature GRC program begins with strategic governance. This layer establishes executive accountability, corporate governance structures, board oversight, policies, and long-term planning.
Without strong governance, organizations struggle with fragmented ownership, inconsistent decision-making, and weak accountability. Leadership must define risk appetite, governance objectives, and operational priorities that align with business strategy.
Key elements include:
Corporate governance
Board oversight and accountability
Policies and procedures
Strategic planning
This layer ensures GRC is treated as a business enabler — not just a compliance requirement.
2. Risk Management
Risk management transforms governance goals into actionable operational processes. Mature organizations continuously identify, assess, mitigate, and monitor risks across cybersecurity, AI, third-party vendors, operations, and regulatory exposure.
An effective risk management layer includes:
Risk identification
Risk assessment and analysis
Risk treatment and mitigation
Risk monitoring and reporting
Organizations that operationalize risk management gain visibility into emerging threats before they become incidents. This is especially critical in modern environments where AI governance, cyber risk, and supply chain risks evolve rapidly.
3. Compliance Management
Compliance management ensures the organization can meet legal, regulatory, contractual, and internal obligations while maintaining operational integrity.
Many organizations make the mistake of treating compliance as isolated audits or annual exercises. Mature GRC programs integrate compliance directly into daily business operations.
Core capabilities include:
Regulatory and legal compliance
Internal controls
Audit and assurance
Incident and non-compliance management
When integrated correctly, compliance becomes proactive instead of reactive.
4. Performance, Controls & Assurance
This layer focuses on validating whether controls are actually working. Policies alone do not reduce risk — effective controls, continuous monitoring, and remediation do.
Mature organizations establish measurable Key Performance Indicators (KPIs) and Key Risk Indicators (KRIs) to evaluate operational effectiveness.
Critical components include:
GRC KPIs and KRIs
Control effectiveness testing
Issue tracking and remediation
Continuous monitoring
This is where organizations build accountability and create confidence with executives, auditors, customers, and regulators.
5. GRC Foundations
The foundation layer creates consistency across the enterprise. Without centralized frameworks, reporting, documentation, and awareness programs, GRC efforts become fragmented and difficult to scale.
This layer includes:
GRC strategy and framework
Policy repositories
GRC reporting and dashboards
Training and awareness
A mature foundation helps organizations standardize governance processes across departments, business units, and global operations.
6. Technology & Data Enablement
Modern GRC cannot scale without technology and automation. Manual spreadsheets and disconnected tools create visibility gaps, inconsistent reporting, and operational inefficiencies.
Technology enables organizations to automate workflows, centralize reporting, integrate data sources, and improve decision-making.
This layer includes:
GRC platforms and tools
Risk and control automation
Data integration
Reporting dashboards
Organizations adopting AI, cloud platforms, and digital transformation initiatives especially need technology-enabled GRC to maintain visibility and control.
Why This Layered Model Matters
The most mature organizations understand that governance, risk, compliance, assurance, and technology are interconnected. Weakness in one layer impacts the effectiveness of the entire program.
A layered GRC operating model helps organizations:
Improve executive visibility
Strengthen accountability
Reduce operational and cyber risk
Enhance audit readiness
Support AI governance initiatives
Accelerate remediation
Enable better business decisions
Most importantly, it transforms GRC from a reactive compliance function into a strategic business capability.
How DISC InfoSec Helps
At DISC InfoSec, we help organizations design and operationalize modern GRC programs that align cybersecurity, compliance, AI governance, and risk management into one integrated operating model.
Our services support organizations with:
GRC program development
AI governance and risk management
Security and compliance assessments
Virtual CISO (vCISO) leadership
Policy and control frameworks
Continuous compliance and reporting
Risk-based security strategy
As regulatory expectations and AI risks continue to evolve, organizations need practical, scalable, and business-aligned GRC programs that go beyond documentation.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
The One Security Book That Got Louder With Every Passing Year
Why Click Here to Kill Everybody by Bruce Schneier belongs on every CISO’s, CAIO’s, and board director’s shelf — in that order
There are security books you read once and shelve. And then there is Bruce Schneier’s Click Here to Kill Everybody, which somehow becomes more relevant every quarter you wait to read it.
Schneier wrote it in 2018. Re-read it in 2026 and you will swear he had a working time machine.
If you are a security or AI governance leader and this book is not already dog-eared on your desk, this post is your nudge. Here is why I keep buying copies for clients, board members, and skeptical CFOs.
The thesis, in one sentence
When every “thing” becomes a computer — your car, your insulin pump, your factory floor, your municipal water system, and now your AI agents — every security flaw becomes a safety flaw.
That sounds obvious until you sit with it. Then it becomes terrifying.
Schneier coined the term “Internet+” to describe the merger of the digital and physical worlds. The internet used to steal your data. The Internet+ can steal your data, crash your car, shut off your pacemaker, and disrupt your power grid. Same vulnerabilities. Vastly different consequences.
This is not hypothetical. It is the world we have already built. Schneier just had the courage — and the receipts — to name it first.
Why this book hits harder in the age of AI
Here is the part that should land for anyone working in AI governance right now.
Schneier’s core argument is about the capability-consequence gap: we deployed connectivity faster than we deployed the governance, accountability, and policy machinery needed to manage its consequences.
Sound familiar?
Replace “IoT” with “generative AI” and “Internet+” with “agentic AI workflows,” and you are reading the playbook for the next five years of enterprise risk. The same market failures Schneier diagnosed — externalized costs, opaque supply chains, asymmetry between attackers and defenders, vendors who treat security as somebody else’s problem — are all reappearing in AI procurement decks today.
If you are implementing ISO 42001, building an AI risk program, or sitting in a room arguing about model approval workflows, this book gives you the moral and economic vocabulary you have been missing.
What you actually get when you read it
This is not a 400-page lecture. Schneier writes like an engineer who learned to talk to lawyers and then learned to talk to everyone else. The book is structured to be useful to three very different readers:
For the technical reader, it is a clear-eyed inventory of why secure-by-default is so hard at scale, why patching is broken, and why software liability has been ducked for thirty years.
For the policy reader, it is one of the most coherent arguments ever published for why cybersecurity is a public-policy problem, not a private one — and what regulation that actually works might look like.
For the executive reader, it is the most useful translation layer you will find between “our threat model” and “our fiduciary duty.” Hand it to a board member who keeps asking why the company can’t just buy a tool to fix this.
The five ideas you will quote for the rest of your career
Without spoiling the book, here are the frames I borrow from Schneier almost weekly with clients:
Security is a property of systems, not products. You cannot bolt it on at the end. (Try telling that to a vendor selling “AI safety” as a feature flag.)
Cheap, networked, and insecure beats expensive and safe — every time — until policy changes the math.
The attacker only has to be right once. The defender has to be right always. Asymmetry is the entire game.
Markets do not fix safety problems. They never have. Aviation, pharmaceuticals, automobiles, food — every safety regime was paid for in bodies before it was paid for in regulation.
Resilience beats prevention. Build systems that fail well, because they will fail.
If any of those land hard, you are ready for the book.
Who this book is for (and who it really is not)
Read it if you are:
A CISO trying to articulate cyber-physical risk to a board that still thinks “cyber” means email phishing.
A Chief AI Officer or vCAIO building governance for systems whose blast radius extends into the physical and economic world.
An auditor, consultant, or implementer working on ISO 27001, ISO 42001, NIST CSF, or the EU AI Act — and looking for the why behind the controls.
A founder shipping connected hardware or AI agents who would rather understand the coming regulation than be surprised by it.
A policymaker, journalist, or director who wants one book that explains the whole landscape without dumbing it down.
Skip it if you are: looking for tactical hardening checklists or a CISSP study guide. This is a strategy book, not a runbook.
My honest take after twenty years in the trenches
I have spent two decades implementing security and governance programs across KPMG, IBM, Intel/McAfee, and now in my own practice — most recently as lead implementer for one of the first ISO 42001 certifications in the financial-data-room space. I have read every framework worth reading and most of the ones that are not.
Click Here to Kill Everybody is one of a very small number of books I re-read every year. Not because the technology stays the same — it absolutely does not — but because the frame Schneier built has aged better than almost any framework I have audited against.
The risks have gotten bigger. The systems have gotten more connected. The governance still lags. Schneier saw it. Read what he wrote.
If you want to discuss how the ideas in this book translate into a working AI governance and ISO 42001 program for your organization — including the parts Schneier could only gesture at in 2018 — that is exactly the work we do at DISC InfoSec.
info@deurainfosec.com
Financial data rooms are the “hard mode” of compliance — if it works there, it works anywhere.
Disc is the Principal Consultant at DISC InfoSec, a boutique AI governance and cybersecurity firm and PECB Authorized Training Partner for ISO 27001 and ISO 42001. He served as lead implementer and internal auditor for ShareVault’s recent ISO 42001 certification.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
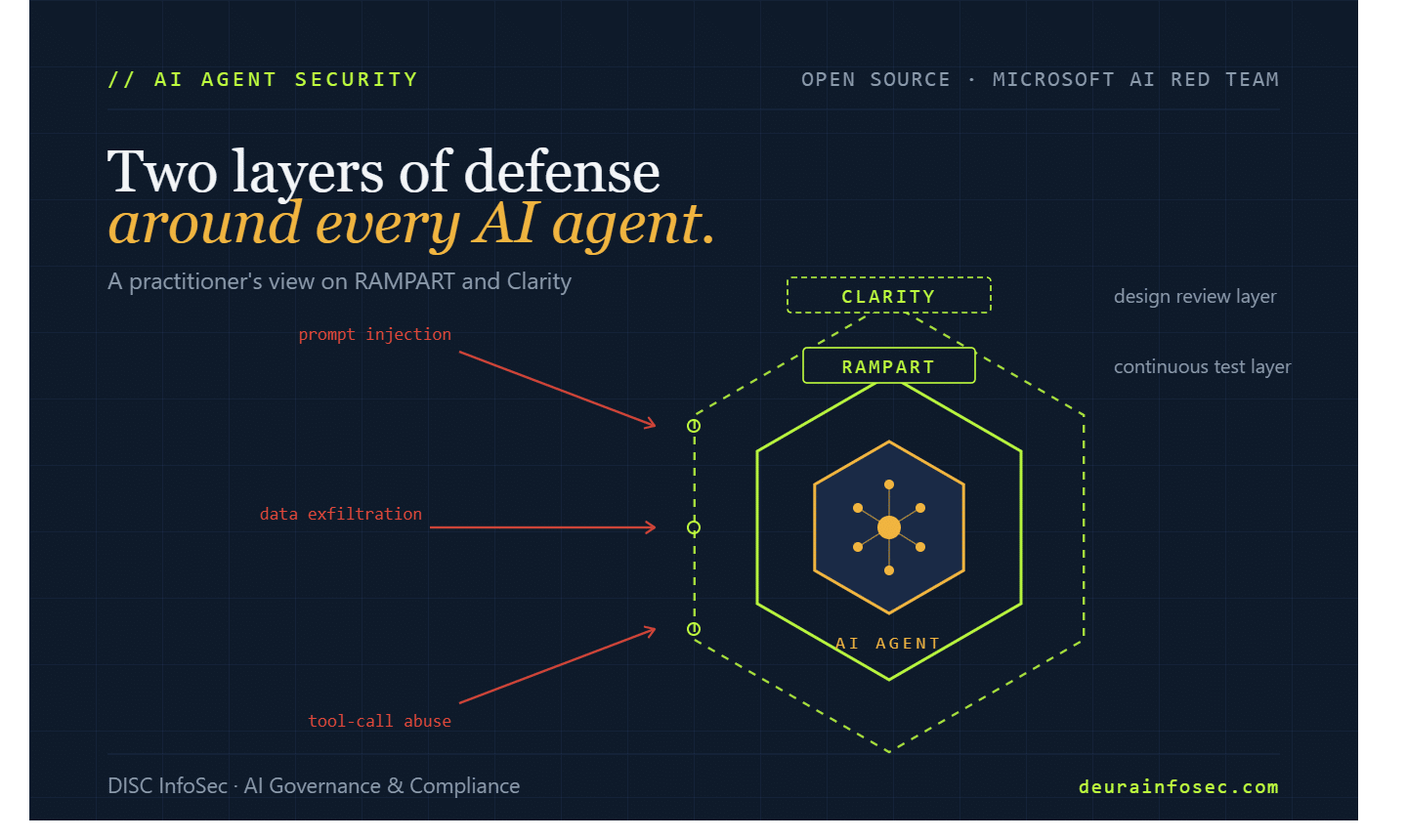
Microsoft Just Open-Sourced the Missing Piece of AI Agent Security: A Practitioner’s Take on RAMPART and Clarity
On May 20, Microsoft’s AI Red Team released two open-source tools that should be on every CISO’s and AI program owner’s reading list this week: RAMPART, a continuous testing framework for AI agents, and Clarity, a structured design-review tool. Both have been battle-tested inside Microsoft before being handed to the community, and together they begin to close one of the most uncomfortable gaps in enterprise AI today — the gap between “we shipped an agent” and “we shipped an agent that holds up under adversarial pressure and audit scrutiny.”
Coming from a practitioner who has spent the last two years implementing ISO 42001 in production environments, my honest reaction: finally. Let me explain why these tools matter, where they fit in a governance program, and where I think organizations will still get this wrong.
What Microsoft Actually Released
RAMPART is a test harness built on top of Microsoft’s existing PyRIT red-teaming library, designed to slot directly into a CI/CD pipeline. Developers write pytest-style tests describing adversarial scenarios — prompt injection, data exfiltration via tool calls, jailbreak attempts — and the framework runs them on every code change. Each test connects through a thin adapter, orchestrates an interaction with the agent, evaluates the outcome, and returns a clear pass/fail signal that can be gated in CI like any other integration test. Because AI systems are probabilistic, RAMPART supports running the same test multiple times and setting a pass threshold rather than demanding deterministic outcomes.
The real-world proof point Microsoft shared is telling: their incident response team took a reported vulnerability, used RAMPART to generate 100 variants of that vulnerability, applied mitigations, and validated each one — collapsing weeks of expert work into hours.
Clarity addresses a different and arguably more expensive failure mode: bad design decisions that become baked into the agent’s architecture. It guides engineers through structured conversations covering problem clarification, solution exploration, failure analysis, and decision tracking. Multiple AI “thinkers” independently examine the proposed system from different angles — security, human factors, adversarial scenarios, operational concerns — and surface the kinds of questions an experienced architect or safety engineer would ask. The output is committed to the repo as human-readable markdown in a .clarity-protocol/ directory, which means design decisions become reviewable artifacts rather than tribal knowledge.
Why This Matters for Security Discipline in Agent Development
Most AI agent failures I’ve seen in client environments don’t trace back to model behavior. They trace back to two earlier failures: nobody wrote down the threat model before the agent was built, and nobody set up continuous adversarial testing after it shipped. RAMPART and Clarity address exactly these two gaps — and they do it in a way that maps cleanly onto how engineering teams already work.
Shifting Agent Safety Left — Without Slowing Anyone Down
The defining problem with AI agent security today is that the testing usually happens in the wrong place at the wrong time. Pre-launch red team engagements are expensive, sporadic, and stale within a sprint. Post-incident reviews are valuable but, by definition, too late. RAMPART changes the economics by making adversarial tests behave like unit tests: cheap to run, repeatable, and enforceable through pull request gating. When a developer adds a new tool to the agent — say, the ability to query a customer database — the safety test for that new capability gets added in the same PR. This is what “secure SDLC” actually looks like for AI agents, and it’s something most internal AI programs have been describing in slide decks but failing to implement in code.
Making Design Decisions Auditable
Clarity is the more underrated of the two tools. ISO 42001, the NIST AI RMF, and the EU AI Act all require organizations to demonstrate that they considered foreseeable risks during system design — not just that they ran some tests at the end. Auditors increasingly ask: “Show me the design review record. Show me the failure modes you considered and the decisions you made.” In most organizations, that record doesn’t exist. It lives in someone’s head, a Slack thread, or a Jira ticket that got closed eight sprints ago. Clarity’s commitment to writing design decisions as markdown artifacts inside the code repo is genuinely useful for compliance evidence — it turns ephemeral architectural conversations into the kind of durable, reviewable record that an ISO 42001 internal auditor or an EU AI Act conformity assessment will ask for.
Closing the “Variant Problem” in AI Incident Response
The detail from Microsoft’s writeup that should grab every incident responder is the 100-variant test. When a real vulnerability is reported in a traditional system, you patch the specific exploit and move on. AI agents don’t work that way. The same underlying weakness can be triggered by hundreds of semantically equivalent prompts, and patching one doesn’t patch the others. RAMPART’s ability to generate variants of a reported vulnerability, test mitigations against all of them, and validate the fix is the kind of capability most enterprise security teams have been trying to build in-house with mixed results. Having Microsoft hand this over as open source — battle-tested against real incidents — meaningfully lowers the cost of doing AI incident response properly.
Where Organizations Will Still Get This Wrong
Tools don’t fix governance gaps. Tools amplify whatever discipline already exists. Three predictions about how RAMPART and Clarity get deployed:
1. Teams will adopt RAMPART without adopting a threat model. RAMPART runs the tests you write. If you only write tests for the prompt injection scenarios you happen to think of, you get a false sense of coverage. Organizations that haven’t done the upstream work of mapping their agent’s attack surface — tool calls, retrieval sources, prompt-completion logging, orchestration handoffs — will end up with a green CI pipeline and the same underlying risk.
2. Clarity will be treated as documentation, not governance. The whole point of structured design reviews is that decisions get challenged before they become technical debt. If Clarity outputs become files that nobody reads in code review, the tool fails. The discipline isn’t in running Clarity. It’s in treating its output as a gate.
3. Both tools will live inside the AI team, not the security organization. This is the failure mode I’ve written about repeatedly. AI agents touch sensitive data, call APIs, and make decisions on behalf of users — they are production systems with security blast radius. If RAMPART and Clarity sit only with the ML engineers and never get visibility from the security team, the org has automated the wrong half of the problem. ISO 42001 explicitly requires defined ownership of AI system risk; this is exactly the kind of shared responsibility these tools enable, if the org bothers to set it up.
My Perspective: This Is the Beginning, Not the End
Microsoft’s release is a meaningful contribution to the AI security commons, but it’s important to be clear-eyed about what it does and doesn’t solve. RAMPART and Clarity are excellent at what they do — adversarial testing in CI and structured design review with artifact output — and they bring genuine engineering rigor to two phases of the AI development lifecycle that have been governed mostly by good intentions.
What they don’t do is replace the broader governance program. An organization that runs RAMPART tests on every PR but has no data classification, no model change management policy, no inventory of which agents are touching which data sources, and no defined accountability for AI risk has automated the testing without building the governance underneath it. These tools are most valuable when they slot into an existing AI management system — ISO 42001 or equivalent — that already defines who is accountable, what risks the organization has accepted, and how evidence gets collected for audit. Without that scaffolding, they become another set of green checkmarks in a dashboard nobody trusts.
The trajectory here is also worth watching. We are moving, fast, toward a world where enterprise procurement asks vendors for evidence of AI agent testing the same way it asks for SOC 2 reports today. The organizations that adopt RAMPART and Clarity now — and, more importantly, build the governance program around them — will be the ones that can answer those procurement questions with confidence in 12 months. Everyone else will be scrambling to retrofit security discipline into agents that are already in production, talking to customers, and quietly accumulating risk.
Microsoft just gave the community two of the right tools. The harder question is whether your organization has the governance discipline to use them well. That part doesn’t come from GitHub.
At DISC InfoSec, we help B2B SaaS and financial services organizations build the AI governance scaffolding — ISO 42001, NIST AI RMF, EU AI Act — that makes tools like RAMPART and Clarity actually deliver value. If you’re standing up an AI agent program and want a practitioner’s view of what holds up under audit, let’s talk.
Turn AI Governance Gaps into Actionable Risk Reduction
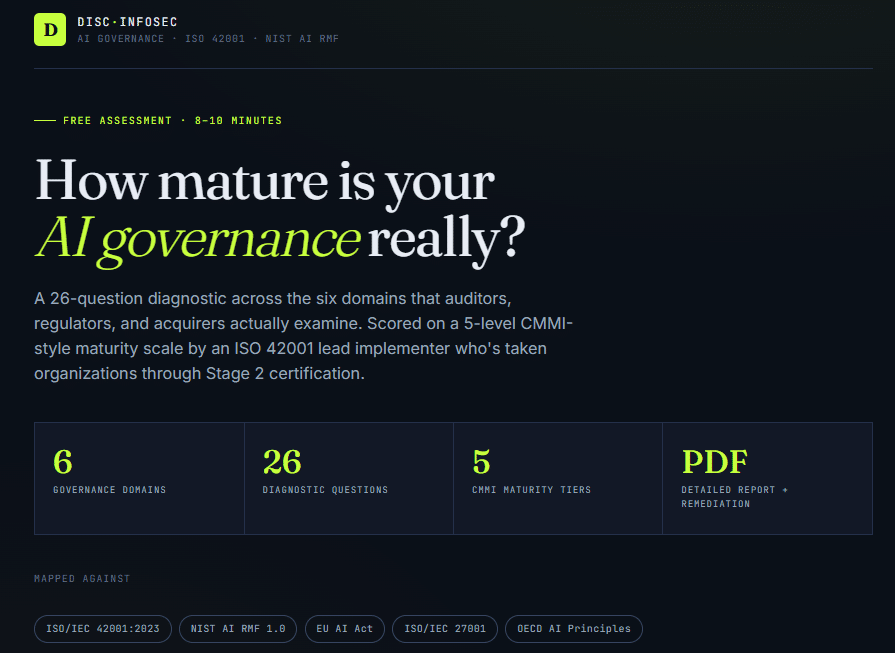
AI adoption is accelerating — but most organizations still lack a clear way to measure whether their AI governance program is secure, compliant, and audit-ready. That’s why DISC InfoSec created the free AI Governance Maturity Calculator — a practical assessment tool designed to help organizations benchmark their AI governance capabilities against leading frameworks including ISO/IEC 42001, NIST AI RMF, OWASP LLM Top 10, and emerging AI regulations.
This isn’t another generic cybersecurity quiz. The calculator evaluates your organization across critical domains such as Governance, AI Security, Compliance, Third-Party Risk, Human Oversight, and Model Monitoring using a 5-level maturity model inspired by CMMI practices. In minutes, organizations receive an instant maturity score, prioritized risk insights, and a detailed downloadable PDF report with remediation guidance, framework references, and the Top 5 Priority Gaps preventing AI governance maturity.
Built by practitioners, not marketers, the tool positions DISC InfoSec as a trusted advisor for organizations navigating AI governance, AI risk management, and regulatory readiness. Whether you are preparing for ISO 42001 alignment, addressing AI compliance obligations, or building defensible AI oversight processes, this free assessment provides an actionable roadmap to strengthen your AI governance program before regulators, customers, or auditors ask the hard questions.
Click the “DISC AI Governance Maturity Calculator” link to begin your assessment.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
The Quiet Truth in the Gen AI Hype: Governance Is the Product
I just finished Generative AI and LLMs For Dummies — a solid primer aimed at executives and non-technical leaders trying to understand what they’ve already bought into. Most of it is what you’d expect: foundation models, transformers, prompt engineering, RAG, vector embeddings.
But buried in the middle of the book is the argument nobody in the LinkedIn AI commentariat wants to spend much time on:
A gen AI system is only as trustworthy as the governance around the data it touches.
That’s the whole post if you want to stop here. For the rest of you — let me unpack what that actually means in practice, because the gap between “we deployed a chatbot” and “we deployed a chatbot a regulator would accept” is wider than most teams realize.
The four governance failure points in a production LLM
When data flows through an LLM-powered application, governance has to follow it across at least four hand-offs:
Training and fine-tuning data — what got fed into the model, and whether you have lineage, classification, and consent for it.
The retrieval layer — what RAG and vector search are pulling back, and whether row-level controls survive the journey from your warehouse into the embedding store.
The prompt-and-completion stream — what users typed in (often sensitive) and what came back (often combining sensitive sources in ways the user wouldn’t have been authorized to query directly).
The orchestration layer — agents calling APIs, chaining prompts, hitting external systems. Each is a fresh data-egress point.
Framing — bring your processing to the data rather than take your data to the processing engine — is the right instinct. The further your data travels from your control plane, the more your governance program becomes a polite suggestion.
The blob-storage problem most teams haven’t thought about
One detail in the book deserves more attention than it gets.
Cloud object stores (S3, Azure Blob, GCS) make it trivial to dump PDFs, audio, video, and chat transcripts into your gen AI pipeline. They do not give you row-level or document-level access controls at the blob level. If your “unstructured data lake” is a bucket with permissive IAM and a service account the AI team uses for retrieval, you’ve quietly created a new exfiltration surface that your DLP tooling probably doesn’t see.
Most of the ISO 42001 gaps I see in client environments live exactly here — at the seam between “we have controls for structured data” and “the AI team is reading from a bucket nobody mapped.”
What good actually looks like
In our ISO 42001 implementation work at ShareVault — a virtual data room serving M&A and financial services clients — the governance challenge wasn’t writing the AI acceptable-use policy. That’s the easy part. The hard part was:
Mapping every data flow that touches an AI system, including the unstructured ones.
Establishing classification labels that travel with the data into embeddings, prompts, and completions.
Logging completions in a way that supports audit without creating a new sensitive-data repository.
Defining model-change management that satisfies ISO 42001 Clause 6.2 and the security controls inherited from ISO 27001.
Financial data rooms are the “hard mode” of compliance — if it works there, it works anywhere. The lesson from running this through a live Stage 2 audit: the model is almost never your biggest risk. The plumbing around the model is.
Three things I’d push every security and AI team to do this quarter
Run an AI data-flow inventory. Not your applications inventory — the actual flow of data into prompts, embeddings, fine-tuning sets, and completions. You will find things you didn’t know existed.
Decide who owns “model + data” risk. Most organizations split this between the AI team and security. That gap is where incidents happen. ISO 42001 forces you to name an owner; do it whether you’re certifying or not.
Treat prompts and completions as production data. They need retention, classification, monitoring, and access policy. Most teams treat them like log files. They’re not.
Where I think this goes — a practitioner’s perspective on the future
The next 24 months in enterprise gen AI will be defined less by model capability and more by which organizations can prove their AI systems are governed. The capability ceiling keeps rising — Claude, GPT, Gemini, Llama, Mistral all get sharper every quarter. But the deployment ceiling is set by trust, and trust is set by governance.
Three things I expect:
Procurement will start asking for ISO 42001. It’s already happening in financial services and healthcare. Within 18 months, expect it in standard B2B SaaS RFPs the way SOC 2 is today.
The shadow-AI problem will get worse before it gets better. Employees are already using gen AI tools nobody inventoried. Governance frameworks that only address policy — and not discovery and enforcement — will fail in production.
The competitive advantage moves to organizations that govern unstructured data well. Roughly 80% of enterprise data is unstructured, and almost no one governs it the way they govern their warehouse. That gap is the next decade of work for everyone in this space.
The models are getting commoditized. Governance isn’t. Build there.
If you’re working through ISO 42001, NIST AI RMF, or the EU AI Act in a serious way and want a practitioner’s view of what actually holds up under audit — that’s most of what we do at DISC InfoSec.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
Managing AI Risk: A Practical Approach to Secure, Responsible, and Effective AI Adoption
Artificial Intelligence is transforming how organizations operate, compete, and innovate. From automating business workflows to enhancing cybersecurity detection and accelerating decision-making, AI offers enormous opportunities. Yet alongside these benefits comes a rapidly expanding landscape of risks that organizations can no longer ignore.
Books like Managing AI Risk help leaders understand that AI implementation is not simply a technology project — it is a governance, security, compliance, and business resilience challenge.
Organizations are rushing to deploy generative AI, large language models (LLMs), autonomous agents, and AI-powered analytics. Unfortunately, many businesses are adopting AI faster than they can govern it.
Today’s AI risks include:
Data leakage through public AI tools
Hallucinations and inaccurate outputs
Prompt injection attacks
AI model manipulation and poisoning
Bias and discrimination in automated decisions
Intellectual property and copyright exposure
Regulatory non-compliance
Shadow AI usage by employees
Lack of transparency and explainability
Overreliance on AI-generated decisions
Cybersecurity teams are now facing a new reality where attackers also use AI to automate phishing, malware development, social engineering, and vulnerability discovery. AI has become both a defensive tool and an offensive weapon.
This creates a critical challenge for leadership: how can organizations embrace AI innovation while still maintaining trust, security, compliance, and operational control?
A Practical and Sensible Approach to AI Implementation
Successful AI adoption requires more than experimentation. Organizations need a structured and practical framework that balances innovation with governance.
A sensible AI strategy should include:
1. AI Governance First
Before deploying AI systems, organizations must establish governance policies defining:
Acceptable AI usage
Risk ownership
Data handling requirements
Human oversight responsibilities
Vendor assessment criteria
Ethical AI principles
Without governance, AI deployments quickly become fragmented and difficult to control.
2. Risk-Based AI Deployment
Not all AI systems carry the same level of risk. Organizations should classify AI use cases based on:
Business impact
Sensitivity of data
Regulatory exposure
Customer impact
Automation level
High-risk AI systems require stronger validation, monitoring, and approval processes.
3. Continuous Security and Monitoring
AI systems are not “set and forget” technologies. Organizations must continuously monitor:
Model drift
Data quality
Security vulnerabilities
User misuse
Adversarial attacks
Compliance violations
AI security must become part of enterprise cybersecurity and GRC programs.
Why an Artificial Intelligence Management System (AIMS) Matters
One of the most important emerging concepts in AI governance is the Artificial Intelligence Management System (AIMS).
An AIMS provides organizations with a formal structure for managing AI responsibly across the enterprise. Similar to how ISO 27001 supports information security management, AI governance frameworks such as International Organization for Standardization ISO/IEC 42001 are helping organizations operationalize AI governance and risk management.
An effective AIMS helps organizations:
Establish AI accountability
Standardize AI governance processes
Improve regulatory readiness
Reduce operational risk
Build stakeholder trust
Align AI initiatives with business objectives
As regulators worldwide continue introducing AI laws and compliance requirements, organizations without structured AI governance will face increasing operational and legal challenges.
The Future of AI and Risk Management
The future of AI risk management will revolve around resilience, transparency, and adaptive governance.
In the coming years, organizations will move beyond basic AI experimentation into enterprise-scale AI ecosystems involving autonomous agents, decision automation, AI copilots, and machine-driven business operations. This evolution will dramatically increase both efficiency and risk exposure.
My perspective is that future AI governance will become deeply integrated with cybersecurity, privacy, enterprise risk management, and compliance functions. AI risk management will no longer be optional — it will become a core business discipline.
We will also see:
Increased global AI regulations
AI security becoming a dedicated cybersecurity domain
Greater emphasis on explainable and auditable AI
Mandatory AI risk assessments
Expansion of third-party AI assurance programs
AI governance becoming part of board-level oversight
Organizations that succeed will not necessarily be the ones adopting AI the fastest, but the ones implementing AI responsibly, securely, and strategically.
At DISC InfoSec, we believe organizations must approach AI with both innovation and discipline. Effective AI governance is not about slowing down adoption — it is about enabling sustainable, trustworthy, and resilient AI transformation.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
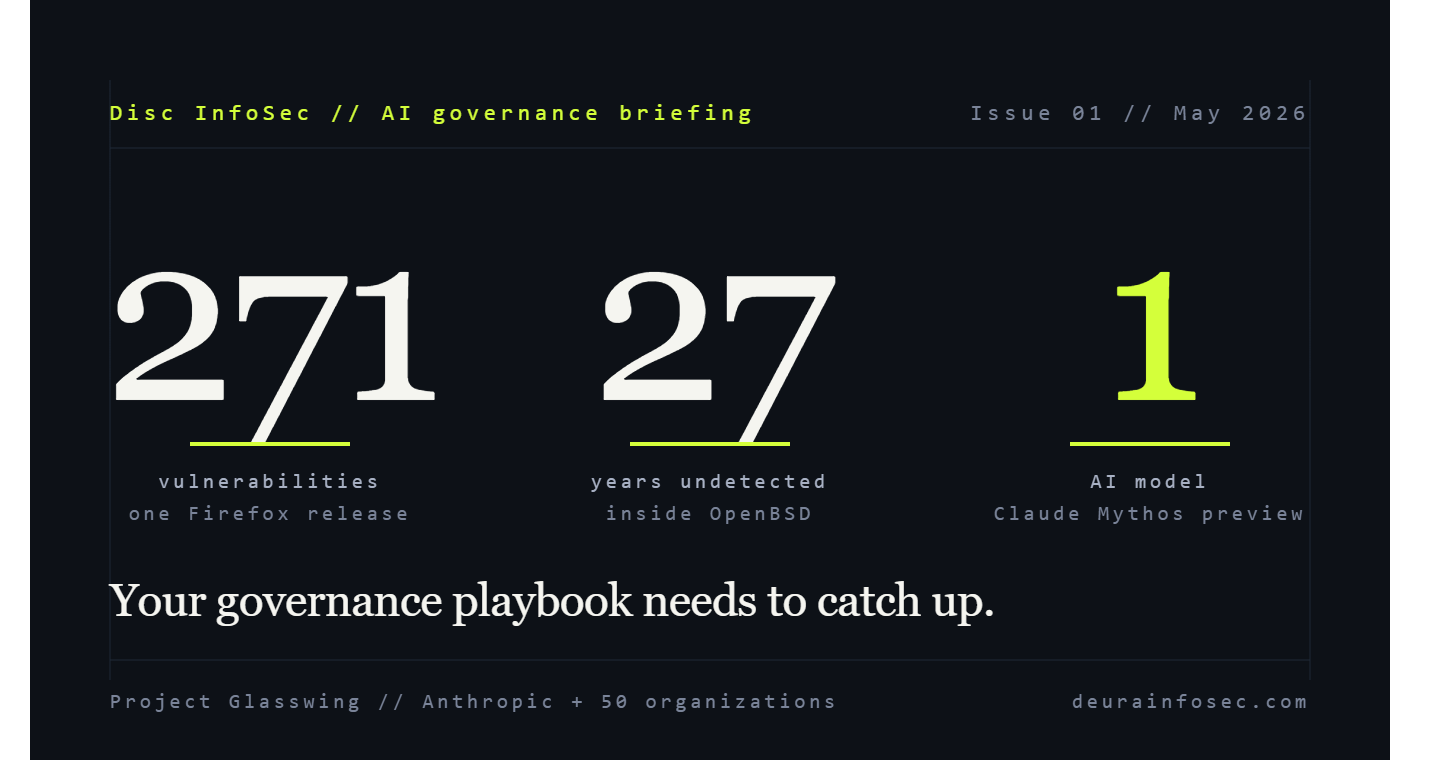
When AI Finds Bugs Humans Missed for 27 Years, Your Governance Playbook Needs to Change
Last month, Anthropic announced Project Glasswing.
Fifty of the most consequential technology and financial institutions on the planet — Apple, Google, Microsoft, AWS, Nvidia, Cisco, Broadcom, Palo Alto Networks, CrowdStrike, JPMorgan Chase, the Linux Foundation, and roughly forty more — are now part of a coordinated effort to use a single AI model, Claude Mythos Preview, to find and fix vulnerabilities in the software the rest of us depend on.
Mozilla has already gone public with results. Firefox 150 shipped with 271 vulnerabilities patched in a single release, surfaced by Mythos in about four weeks of focused work. One of those bugs had quietly survived 27 years inside OpenBSD — an operating system whose entire identity is built around being unbreakable.
Read that again. Twenty-seven years of expert human review missed what an AI surfaced in under a month.
That’s the headline. The headline isn’t the story.
The real story is what this does to governance
For two decades, the answer to “how do I trust this software?” has been a stack of artifacts: SOC 2 reports, penetration tests, vendor questionnaires, patch cadence policies. Those artifacts assume a world where vulnerability discovery is bottlenecked by human expertise.
That assumption just broke.
When one AI can audit every line of code in a major operating system and write working exploit code for the bugs it finds, three things move at the same time:
The bar for “reasonable security” shifts. Insurers, regulators, and enterprise buyers will start asking whether vendors use AI-assisted code review. Vendors who can’t answer cleanly will be a different risk category by 2027.
The window between patch and exploit collapses. Attackers have always reverse-engineered patches. AI compresses that work from days to minutes. If your mean time to patch critical vulnerabilities is north of 30 days, that window is materially more dangerous than it was last year.
Disclosure infrastructure shows its age. CISA’s coordinated disclosure process and the CNA framework were designed for human-paced research. They were not built for a coalition of fifty organizations running a model that finds thousands of zero-days on a quarterly cadence.
Where AI Governance comes in
I’ve spent the last two years implementing ISO/IEC 42001 in production — including taking ShareVault, a virtual data room serving M&A and financial services clients, through a successful Stage 2 audit.
That work taught me one thing clearly: AI governance is not a downstream compliance exercise. It’s the operating layer for trust.
Glasswing is the most visible signal yet that the governance question is moving from “should we use AI in security-critical workflows?” to “what controls govern its use, who has access, and how do we verify the answers?” That’s the question every framework — ISO 42001, NIST AI RMF, the EU AI Act — was built to answer. Most organizations haven’t actually mapped controls to use cases yet. The ones who do this quarter will own the conversation in 2027.
Your next quarterly agenda
Update vendor due diligence. Add one question to every security review: “Do you use AI-assisted code review or vulnerability scanning, and what governance controls sit around it?” You don’t need a perfect answer. You need to know who’s thinking about it.
Validate actual patch performance — not the policy, the numbers. Mean time to patch critical CVEs is now a material disclosure conversation.
Call your cyber insurance broker and ask whether AI-audited code is showing up in renewal questionnaires yet. If not this year, when. Get ahead of the question.
Map this to your AI governance framework. ISO 42001, NIST AI RMF, and the EU AI Act give you the scaffolding. Skip the mapping exercise and you’ll be re-engineering it under audit pressure.
Brief your board. Not on the technology. On the shift in what “reasonable security” now means.
Where this goes next
Glasswing is a coalition of fifty today. Capabilities like Mythos always proliferate — Anthropic itself estimates comparable models will be broadly available within 6 to 18 months. When that happens, defenders lose their head start.
Here’s where I think the next two years go:
AI governance becomes the language of trust. Procurement, insurance, and audit conversations will increasingly turn on whether you can produce evidence — not policy, evidence — that your AI use is governed. ISO 42001 certifications and EU AI Act conformity assessments will start showing up in RFP scoring criteria the way SOC 2 did a decade ago.
The “vCAIO” role becomes real. Most mid-market companies will not hire a full-time Chief AI Officer in 2026 or 2027. They will retain fractional governance leadership the same way they did with vCISOs after 2015. The work is similar: control mapping, risk register, board reporting, audit readiness.
Tools without process will look like theater. The organizations that come out ahead won’t be the ones that panic-buy an AI security platform. They’ll be the ones that built the governance muscle — control mappings, role definitions, audit evidence, escalation paths — before the capability was everywhere.
Financial data rooms are the hard mode of compliance. If governance works there, it works anywhere. That’s the bar I’ve been holding myself to, and it’s the bar I’d encourage you to hold your vendors to.
One question for you: Do you actually know whether the vendors in your stack use AI in their code review process? If you don’t — that’s the conversation to start this week.
If you’re working through what Glasswing-class capabilities mean for your AI governance program, I’m happy to think it through with you. DM me below.
Disc | Principal Consultant, DISC InfoSecISO 42001 & ISO 27001 Lead Implementer | CISSP, CISM | PECB Authorized Training PartnerLead implementer for ShareVault’s ISO/IEC 42001 certification — passed Stage 2 audit
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
AI security spans a broader attack surface than traditional infosec because the model itself is now part of what you’re defending. The pillars most practitioners converge on:
Data security and integrity. Training, fine-tuning, and RAG data are all attack surfaces. Poisoning, label flipping, and backdoor insertion happen upstream; data lineage, provenance tracking, and integrity controls are the defense. This is also where most privacy obligations land (PII minimization, retention, consent).
Model security. Protecting the model itself from adversarial inputs (evasion), model extraction/stealing, membership inference, and inversion. Includes hardening against prompt injection and jailbreaks for LLMs, which behave differently from classical adversarial ML threats.
Access and identity. Who can query, fine-tune, deploy, or modify a model — and under what authorization. RBAC/ABAC on inference endpoints, secrets management for API keys, separation of duties between data science, MLOps, and production. Often the weakest link in real-world incidents.
Supply chain. Pre-trained foundation models, open-source libraries, HuggingFace artifacts, datasets, and embedding providers all enter your trust boundary. SBOM-equivalents for ML (model cards, dataset cards, signed artifacts) and vendor due diligence are increasingly non-negotiable.
Infrastructure and MLOps security. The pipelines, notebooks, registries, feature stores, and orchestration layers — most of which were built for velocity, not security. Standard cloud/container hardening applies, plus pipeline-specific concerns like notebook sprawl and unsecured model registries.
Output and content safety. Guardrails against harmful, biased, hallucinated, or leaked outputs. For agentic systems this expands to tool-use safety, sandboxing, and constraining what actions a model can take downstream of a malicious prompt.
Monitoring, detection, and observability. Drift, anomaly detection on inputs/outputs, abuse pattern detection, and audit logging sufficient to reconstruct an incident. Most orgs underinvest here relative to classical SIEM coverage.
Governance and assurance. The wrapper that makes the rest defensible to auditors, regulators, and customers — ISO 42001, NIST AI RMF, EU AI Act obligations, internal AI use policies, risk registers, and impact assessments. Without this, the technical controls have no organizational accountability behind them.
Resilience and incident response. Red-teaming (both classical and AI-specific), tabletop exercises that include model failure modes, rollback capability for compromised models, and IR playbooks that recognize a poisoned model or a prompt-injected agent as a real incident class.
The practitioner shorthand I’d use: classical CIA still applies, but you’ve added a model that can be attacked, a pipeline that can be poisoned, and an output channel that can be weaponized — so you need controls at each of those layers plus the governance to prove the controls exist.
Here’s the same set of pillars reframed as an accountability matrix, then a candid take on what actually works in implementation.
Pillar
Primary Owner
Oversight Authority
Audit Cadence
Monitoring Cadence
Data security & integrity
Data Owner / CDO (with Security as partner)
CISO + DPO; AI Governance Committee for high-risk datasets
Annual formal audit; ad-hoc on schema or source changes; per-release for training data
Annual IR plan review; semi-annual tabletop incl. AI-specific scenarios
Continuous detection; quarterly drills; post-incident reviews on every Sev-2+
A few notes on how to read this matrix in practice. Primary Owner is who builds and runs the control; Oversight Authority is who signs off that it’s working and gets fired if it isn’t — those should never be the same person. Audit cadence is the minimum floor; trigger-based audits (model retraining, vendor change, regulatory update, security incident) almost always matter more than the calendar. Monitoring cadence is calibrated to risk tier — a high-risk EU AI Act system gets continuous output sampling; an internal productivity tool gets weekly.
My perspective on implementation and monitoring
Most orgs get the matrix roughly right on paper and then fail in three predictable ways.
First, ownership ambiguity at the seams. Data security is “owned” by the data team, model security by ML engineering, supply chain by procurement — and the seams between them are where incidents happen. A poisoned third-party dataset is a supply chain failure that becomes a data integrity failure that becomes a model security failure. If you can’t name a single accountable person for cross-pillar incidents (in most orgs, that’s the CAIO or vCAIO function), the matrix is decorative. The fix is a RACI that explicitly forces a single accountable owner per AI system end-to-end, not per pillar.
Second, monitoring theater. Continuous monitoring gets written into every policy and then implemented as a dashboard nobody opens. The pillars where this fails hardest are output safety and model security — both require sampling and human review, not just telemetry. A useful test: if your AI monitoring would not catch a slow drift that degrades outputs over six months, you don’t have monitoring, you have logging. Build at least one human-in-the-loop checkpoint per high-risk system, and treat the sampling rate as a control to be audited.
Third, audit cadence misaligned with model lifecycle. Annual audits are an artifact of financial reporting cycles, not AI risk. Models change faster than audit cycles — a quarterly cadence for high-risk systems is the realistic floor, with trigger-based reassessment on retraining, material data source change, or material behavior change. ISO 42001 surveillance gives you the annual external check; your internal cadence has to be tighter than that to actually catch things between surveillance visits.
The pillar that’s chronically under-resourced is governance and assurance, and it’s the one that determines whether everything else is defensible. Without a documented risk register, control mapping (NIST AI RMF + ISO 42001 + sector-specific), and board-level reporting, the technical controls exist but can’t be proven to exist — which fails every audit, every customer security questionnaire, and every regulator inquiry. That’s why the practitioner pattern that actually works is: build the governance layer first (even thin), then layer technical controls into it. The reverse — strong technical controls with no governance wrapper — is what we see in most “we have AI security” pitches, and it collapses the first time someone asks for evidence.
The honest summary: technical controls are the easy part; the hard part is sustained ownership, sampling discipline, and auditable evidence. The orgs that pass real ISO 42001 Stage 2 audits aren’t the ones with the fanciest guardrails — they’re the ones that can produce the access review from last Tuesday and the red-team report from last quarter without scrambling.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
METATRON: The First Practical Glimpse of Local-AI Penetration Testing — And Why AI Governance Teams Should Care
An InfoSec, compliance, and AI governance perspective from DISC InfoSec
In our recent post “Why Run LLMs Locally? The Future of Private Enterprise AI”, we made the case that the next phase of enterprise AI maturity will be measured by control, not capability. Cloud LLMs gave us speed. Local LLMs give us sovereignty, auditability, and defensibility — the three things every InfoSec and compliance program is now being asked to prove.
We closed that post by flagging an emerging tool worth watching: METATRON.
This is the deeper look.
What Is METATRON?
METATRON is an open-source, CLI-based penetration testing assistant that runs entirely on the operator’s local machine — no cloud, no API keys, no third-party subscriptions, no data leaving the host.
You feed it a target IP or domain. It autonomously orchestrates a stack of standard reconnaissance tools (nmap, nikto, whois, dig, whatweb, curl), pipes the raw output into a locally hosted, fine-tuned LLM, and the model performs the analysis — identifying services, flagging probable vulnerabilities, cross-referencing CVEs, and recommending fixes. Everything is persisted to a five-table MariaDB schema with full audit history and exportable PDF/HTML reports.
A few specifics worth pinning down:
Language / runtime: Python 3, CLI
AI model:metatron-qwen, a fine-tuned variant of huihui_ai/qwen3.5-abliterated:9b
LLM runner: Ollama, running on-device
Model parameters: 16,384-token context window, temperature 0.7, top-k 10, top-p 0.9 — tuned for technical precision, not creative output
OS target: Parrot OS / Debian-based Linux
Hardware floor: ~8.4 GB RAM for the 9B model (a 4B variant is available for lighter rigs)
The two architectural choices that matter most for an AI governance practitioner:
An agentic loop. The model can autonomously request additional tool executions mid-analysis if it needs more data before rendering a verdict. This is genuine iterative reasoning, not a single-pass scan.
A zero-exfiltration guarantee. Because inference runs locally through Ollama, target data — internal IP ranges, banner information, discovered vulnerabilities, exploit attempts — never leaves the tester’s machine.
That second point is the headline. We’ll come back to it.
How METATRON Strengthens AI Governance Controls
If you’re implementing an AIMS under ISO/IEC 42001, mapping to NIST AI RMF, or preparing for the EU AI Act, here’s where METATRON’s architecture maps onto real control requirements rather than slideware.
1. Data sovereignty becomes a default, not a policy fiction
Most AI tools force a difficult conversation with your DPO or compliance lead: “What happens to the data we feed the model?” With cloud-AI pentest assistants, your answer typically involves vendor TOS, retention windows, and cross-border data transfer clauses you may or may not have negotiated.
With METATRON, the answer is structurally simple: nothing leaves the host. That single architectural property satisfies:
ISO 27001:2022 A.5.14 (Information transfer) — no external transfer occurs
ISO 42001 Annex A controls on data handling and third-party AI services — the AI provider is you
GDPR Article 28 / SCCs — there is no processor to assess; cross-border transfer is moot
Internal data residency commitments to enterprise customers — the assertion becomes verifiable, not aspirational
This is the same architectural principle we lean on when advising regulated clients. Financial data rooms are the “hard mode” of compliance — if it works there, it works anywhere — and the same logic applies to security tooling.
2. Auditability is built in, not bolted on
The five-table MariaDB schema (history, vulnerabilities, fixes, exploits_attempted, summary) keyed by session number isn’t just engineering tidiness. It’s an audit trail.
For AI governance, this matters because regulators and auditors are increasingly asking the same questions of AI-assisted security work that they ask of AI-assisted business work:
Who ran the AI?
Against what target?
What did the model output?
What action was taken on that output?
Can you reproduce the analysis?
METATRON answers all five by design. That maps cleanly to ISO 42001 Clause 8 (Operation) and Clause 9 (Performance evaluation), and to the NIST AI RMF MEASURE function — specifically the obligation to log, retain, and review AI system outputs.
Exportable PDF/HTML reports give you something to attach to a finding, a client deliverable, or an audit working paper.
3. Third-party AI risk drops to near-zero for this workflow
The fastest-growing category of Shadow AI in security teams is not ChatGPT — it’s pentesters and SOC analysts pasting sensitive data into cloud LLMs to accelerate analysis. We’ve seen it in vendor assessments. We’ve seen it in internal audit walkthroughs. It is everywhere.
METATRON removes the temptation. The local model is good enough to be useful, the workflow is purpose-built, and there’s no cloud endpoint to send anything to. For a CISO trying to enforce an Acceptable Use of AI Tools policy under ISO 42001 Annex A.3, that’s a structural win, not a training problem.
4. It pressure-tests AI-deployed environments using AI-native tooling
This is the meta-point. If your organization is shipping AI features, your attack surface now includes prompts, embeddings, vector stores, model endpoints, and orchestration plumbing — none of which traditional pentest workflows fully cover.
METATRON’s agentic loop is, in effect, a small example of the architecture you’re trying to defend. Operating it gives security teams direct, hands-on exposure to:
Local model serving (Ollama)
Context-window management
Agentic tool dispatch and prompt routing
LLM output validation against structured tooling
That’s not a curriculum. That’s practice. And practice is what builds AI security maturity faster than any framework alone.
Why You Should Have It on Your Bench Today
A few honest reasons, not marketing reasons.
1. The AI pentesting tooling landscape is consolidating fast. METATRON, Apex, pentest-ai-agents, CVE MCP Server — within a single quarter we’ve seen multiple credible entrants. Getting hands on the open-source ones now is how you stay literate before clients and auditors start asking which you use.
2. Auditors are starting to ask AI-specific testing questions. “Have you tested your AI system’s attack surface?” is a question on more audit checklists every quarter. Saying “yes, with a tool that runs entirely on-prem and produces a defensible audit trail” is materially stronger than “yes, we used a cloud service.”
3. The Shadow AI problem inside security teams is real. If your pentesters and analysts are already using cloud LLMs to speed up analysis, you have a data-exfiltration risk you may not be tracking. A local alternative gives you something to migrate them to.
4. The cost is your time, not your budget. MIT-licensed, free, no subscription. The only meaningful cost is the GPU/RAM to run the model. If you’re already running local LLM experiments — and you should be — the marginal cost is roughly zero.
5. It’s a teaching environment. For internal training on local AI, prompt engineering for technical workflows, and agentic orchestration, METATRON is one of the more concrete sandboxes available right now.
How to Install METATRON
Below is the consolidated install path, distilled from the project’s README. Run it on Parrot OS or another Debian-based distribution. Plan for around 8.4 GB of free RAM for the 9B model (use the 4B variant on lighter hardware).
⚠️ Legal note up front: This is offensive security tooling. Only run it against systems you own or have explicit written authorization to test. Unauthorized scanning is illegal.
Step 1 — Clone the repository
git clone https://github.com/sooryathejas/METATRON.git
cd METATRON
CREATE DATABASE metatron;
CREATE USER 'metatron'@'localhost' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON metatron.* TO 'metatron'@'localhost';
FLUSH PRIVILEGES;
EXIT;
🔐 Hardening note: The default credentials in the README (metatron / 123) are fine for a lab. Do not ship them. Rotate immediately, store the new password in a vault, and restrict the MariaDB bind address to localhost.
Then create the five tables exactly as defined in the project’s README (history, vulnerabilities, fixes, exploits_attempted, summary). The schema is short and worth pasting verbatim from the source — see the GitHub repo for the canonical DDL.
Step 8 — Run it
You need two terminals.
Terminal 1 — load the model:
ollama run metatron-qwen
Wait for the >>> prompt. Leave it running.
Terminal 2 — launch METATRON:
cd ~/METATRON
source venv/bin/activate
python metatron.py
From the main menu, pick [1] New Scan, enter a target you’re authorized to test, and choose the recon tools to run. METATRON handles the rest — orchestration, LLM analysis, CVE lookups, persistence, and report generation.
My Perspective
A few practitioner-grade observations to close.
This is an early tool, not a managed product. With 44 stars on GitHub and four commits at the time of writing, METATRON is a research-grade project from a single author. That’s a feature, not a bug — it’s the right time to evaluate it, understand the architecture, and decide whether to fork, contribute, or wait. But don’t put it on a production engagement until you’ve vetted the codebase yourself.
The local LLM is the real innovation here, not the recon stack.nmap and nikto orchestration has existed for two decades. What’s new is the deterministic privacy posture of the analysis layer. That’s the part worth studying, because the same architectural pattern — local model + structured tool dispatch + persistent audit trail — is what AI governance teams are going to want for every sensitive AI workflow, not just pentesting.
Treat the AI output as a first opinion, not a verdict. The model is fine-tuned for technical analysis, but it’s still a 9B-parameter model running on a laptop. Cross-reference CVE findings, validate exploit suggestions, and remember that the temperature 0.7 setting means the output isn’t deterministic. For ISO 42001 conformance, this is exactly the kind of human-in-the-loop control you’d document under A.6.2.6 (Human oversight) and A.9.3 (Use of AI systems).
The hard problems METATRON doesn’t solve are also worth naming. It doesn’t address prompt injection of the LLM itself, doesn’t sandbox the recon tools, doesn’t enforce scope boundaries against unauthorized targets, and doesn’t include a safety layer to prevent operator misuse. Each of those is something a mature program should layer around the tool, not assume the tool provides.
Where this fits in a real practice. For DISC InfoSec’s clients — and frankly for any organization implementing ISO 42001 — METATRON is most valuable as a demonstration platform: a hands-on way to show executives, auditors, and engineering teams what “AI inside the security perimeter” actually looks like. It is much easier to govern something you have touched than something you have only read about.
The organizations that learn to operate local AI tooling now — under their own roof, on their own hardware, against their own audit trail — are the ones that will pass the AI governance audits of 2027 without breaking a sweat.
METATRON is one place to start.
Need help building an AI governance program that holds up to a real Stage 2 audit? DISC InfoSec is an active ISO/IEC 42001 implementer and PECB Authorized Training Partner. email: info@deurainfosec.com.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
In today’s cybersecurity and AI governance landscape, resilience is not built on optimism — it is built on preparedness. A core principle echoed throughout modern security frameworks is that organizations should never rely on the assumption that threats will not materialize. Instead, they must invest in the readiness, controls, and governance structures necessary to withstand inevitable attacks and disruptions.
This perspective closely aligns with a timeless strategic principle from The Art of War: success is not determined by the hope that adversaries will refrain from attacking, but by ensuring that your defenses, processes, and operational posture are fundamentally resilient.
For information security leaders, this translates into adopting a proactive security model:
Zero Trust architectures instead of perimeter assumptions
Continuous monitoring rather than periodic audits
AI governance frameworks that anticipate misuse, bias, and regulatory scrutiny
Incident response capabilities that assume compromise scenarios
Compliance programs designed for operational resilience, not checkbox certification
In AI governance specifically, organizations cannot assume that AI systems will always behave predictably or ethically under real-world conditions. Responsible deployment requires rigorous model oversight, transparency controls, human accountability, adversarial testing, and ongoing risk assessments. The question is no longer if systems will face manipulation, drift, or misuse — but whether governance structures are mature enough to respond effectively.
Similarly, modern compliance has evolved beyond static policy documentation. Regulators increasingly evaluate whether organizations can demonstrate operational trustworthiness, cyber resilience, and defensible governance practices under pressure.
The strategic lesson is clear: resilient organizations do not build security around the absence of threats; they build confidence around their ability to endure them.
Perspective
The future of cybersecurity and AI governance will favor organizations that institutionalize resilience as a business capability rather than treat security as a reactive function. As AI systems become more autonomous and regulatory expectations continue to expand, preparedness, transparency, and adaptive governance will become defining competitive advantages.
In this environment, the strongest organizations will not be those that avoid attacks entirely — they will be the ones designed to remain trustworthy, compliant, and operational even when attacks inevitably occur.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
Why Local LLMs Matter for Security, Privacy, and AI Governance – Make sure to check out METATRON in the final thoughts section.
Artificial Intelligence is rapidly becoming part of everyday business operations. From drafting policies and summarizing meetings to analyzing contracts and automating workflows, Large Language Models (LLMs) are now embedded into enterprise decision-making. But as organizations adopt AI at scale, a critical question emerges:
Should your AI run in the cloud — or on your own infrastructure?
For many organizations, especially in cybersecurity, compliance, healthcare, finance, legal, and government sectors, running LLMs locally is no longer just a technical experiment. It is becoming a strategic business decision.
Cloud AI platforms offer convenience and instant scalability, but they also introduce concerns around privacy, data sovereignty, operational costs, and dependency on external providers. Local LLMs shift that control back to the organization.
According to the ApXML guide on local LLMs, one of the biggest advantages of running models locally is that prompts and outputs never need to leave your environment, significantly improving privacy and control over sensitive information.
Privacy and Data Security
Privacy is the primary driver behind the rise of local AI deployments.
When users interact with cloud-based AI systems, prompts, uploaded documents, and generated outputs are often processed on third-party infrastructure. Even when providers promise strong security controls, organizations still face concerns around:
sensitive intellectual property exposure
regulated data handling
insider threats
cross-border data transfers
vendor retention policies
Running LLMs locally keeps the data inside your own security perimeter.
This matters enormously for:
legal contracts
patient records
internal audit reports
source code
financial forecasts
security investigations
AI governance documentation
Recent enterprise AI research also highlights growing concerns around data leakage in Retrieval-Augmented Generation (RAG) systems and fine-tuned enterprise assistants. Researchers argue that deterministic access control and local governance mechanisms are essential for protecting confidential enterprise information.
For InfoSec and compliance teams, local AI aligns naturally with:
zero trust architectures
data residency requirements
AI governance programs
confidential computing initiatives
internal audit controls
Cost Predictability
Cloud AI services typically charge based on tokens, requests, storage, or inference time. Initially this appears inexpensive, but costs can escalate rapidly once AI becomes embedded into daily workflows.
Organizations using AI for:
large-scale document analysis
internal copilots
AI agents
coding assistants
customer support
automated compliance reviews
often discover that API expenses become difficult to forecast.
Running LLMs locally changes the economics. Instead of recurring token-based billing, organizations invest in infrastructure once and gain predictable operational costs afterward.
This becomes especially valuable for:
high-volume workloads
long-context processing
internal enterprise AI tools
continuous experimentation
multi-agent systems
For startups and SMBs, local AI can also reduce dependence on expensive subscription ecosystems.
Offline Access and Air-Gapped Operations
Cloud AI fails when internet access fails.
Local LLMs continue functioning even:
during outages
in restricted environments
on isolated networks
in field deployments
inside air-gapped systems
This capability is increasingly important for:
defense contractors
manufacturing facilities
critical infrastructure
healthcare environments
regulated enterprises
Many organizations cannot legally or operationally send sensitive information to external AI providers. In these cases, local AI is not merely preferred — it becomes mandatory.
Lower Latency and Faster Internal Workflows
Local inference often delivers lower latency because requests do not travel across the internet to external providers.
For internal enterprise tools, this can significantly improve:
coding assistants
SOC analyst workflows
security triage systems
AI-powered search
desktop copilots
document retrieval systems
Local models can feel more responsive and predictable because organizations fully control the infrastructure and workload prioritization.
Customization and Model Freedom
Cloud providers usually limit users to a curated set of models and APIs. Local deployment opens access to the broader open-source ecosystem.
Organizations can experiment with:
Meta Llama
Alibaba Cloud Qwen
Mistral AI Mistral
fine-tuned domain-specific models
quantized lightweight models
multimodal architectures
This flexibility enables organizations to:
optimize models for specific workflows
fine-tune on proprietary datasets
enforce internal AI governance policies
create specialized AI agents
integrate custom security controls
Local deployment also reduces vendor lock-in, allowing teams to evolve their AI stack without depending entirely on a single provider.
AI Governance and Compliance Advantages
AI governance is becoming one of the strongest arguments for local deployment.
As regulations evolve, organizations increasingly need to demonstrate:
where data is processed
who accessed the AI system
how prompts are retained
how outputs are audited
whether inference occurred securely
Recent discussions around Confidential AI and verifiable inference show that enterprises now expect not only secure AI systems, but proof that sensitive data remained protected during inference.
Local AI environments simplify:
auditability
logging controls
access management
compliance mapping
risk assessments
retention governance
For AI GRC teams, this becomes a foundational capability rather than a convenience.
Better Learning and AI Engineering Maturity
Running LLMs locally forces organizations to understand how AI systems actually work.
Teams gain practical experience with:
GPUs
quantization
inference optimization
vector databases
orchestration frameworks
model routing
AI security controls
Interestingly, many AI engineers argue that local models encourage better system architecture design because developers must think carefully about workflows, modularity, and resource optimization rather than relying entirely on brute-force cloud inference.
This often produces more resilient and scalable AI systems in the long run.
The Trade-Offs
Local LLMs are not perfect.
Organizations must still address:
GPU costs
infrastructure management
model updates
operational maintenance
performance tuning
scalability
security hardening
Cloud AI platforms still dominate when organizations prioritize:
simplicity
rapid deployment
frontier-model performance
elastic scalability
For many enterprises, the future will likely be hybrid:
sensitive workloads run locally
non-sensitive workloads use cloud AI
governance policies determine routing dynamically
This hybrid strategy balances innovation with control.
Final Thoughts
Running LLMs locally is not about rejecting cloud AI. It is about strategic control.
As AI becomes deeply integrated into enterprise operations, organizations are realizing that:
privacy matters
governance matters
auditability matters
predictability matters
ownership matters
Local AI deployment transforms LLMs from external services into internal infrastructure.
For cybersecurity leaders, compliance professionals, and AI governance teams, that shift is profound.
The organizations that master local AI today will likely have a significant advantage tomorrow — not just in security and compliance, but in resilience, innovation, and long-term AI independence.
🚨 METATRON is an emerging open-source AI-powered penetration testing assistant designed for fully offline security assessments. Built for Parrot OS and other Debian-based Linux distributions, it combines automated reconnaissance tools with locally hosted LLM analysis, removing the dependency on cloud APIs or third-party services. Written in Python 3, this CLI-based framework can autonomously coordinate recon and vulnerability assessment tasks against target IPs or domains, making it an interesting addition for security researchers and red teams exploring private, local AI-driven offensive security workflows.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
As enterprise AI adoption accelerates, AI Model Risk Management is rapidly becoming one of the most important disciplines in modern governance, risk, and compliance programs. Organizations are no longer experimenting with isolated AI models — they are deploying AI across critical business operations, customer interactions, analytics, automation, and decision-making systems. With that scale comes a new category of operational, regulatory, and security risk that cannot be ignored.
The market momentum reflects this shift. The AI Model Risk Management market is projected to grow from USD 5.7 billion in 2024 to USD 10.5 billion by 2029, representing a strong CAGR of 12.9%. This growth highlights a broader reality: organizations now recognize that AI innovation without governance creates significant exposure across compliance, cybersecurity, reputational trust, and business resilience.
Several major drivers are accelerating investment in AI risk management programs. Security leaders are facing increasing cyber threats targeting AI systems, including model manipulation, prompt injection, data poisoning, and unauthorized model access. At the same time, regulators worldwide are introducing stricter AI governance requirements focused on transparency, accountability, explainability, and ethical AI deployment.
Another major factor is the growing need for automated risk assessment and lifecycle visibility. AI models are dynamic systems that evolve over time, making continuous oversight essential. Without proper controls, organizations risk model drift, inaccurate predictions, biased outcomes, compliance failures, and operational instability that can directly impact business performance and customer trust.
The rise of Generative AI and agentic AI systems is also creating new opportunities and new governance challenges. Organizations are investing heavily in AI-powered decision support, copilots, autonomous workflows, and intelligent automation. These technologies offer enormous business value, but they also introduce complex risks around data privacy, hallucinations, excessive permissions, intellectual property exposure, and accountability gaps.
A strong AI Model Risk Management program typically follows a structured five-stage lifecycle approach. The first stage is Identification — understanding what could go wrong. This includes identifying vulnerabilities, ethical concerns, model weaknesses, bias risks, and business impact through assessments, audits, and impact analysis.
The second stage is Assessment, where organizations evaluate the severity, likelihood, and operational impact of identified risks. This step helps prioritize remediation efforts while measuring model reliability, explainability, resilience, and alignment with business objectives and regulatory expectations.
The third stage is Mitigation, which focuses on reducing risk through safeguards and controls. Organizations may retrain models, improve data quality, implement human oversight, strengthen explainability, apply access controls, and establish governance guardrails to minimize exposure and improve trustworthiness.
The fourth and fifth stages — Monitoring and Governance — are where mature AI programs separate themselves from basic AI deployments. Continuous monitoring helps detect model drift, abnormal behavior, and emerging threats in real time, while governance ensures policies, accountability, compliance obligations, and executive oversight remain active throughout the AI lifecycle.
Effective AI Model Risk Management ultimately delivers measurable business value. It reduces bias, strengthens trust in AI-driven decisions, improves compliance readiness, minimizes financial and reputational exposure, and enables organizations to scale AI responsibly with confidence. In today’s environment, AI governance is no longer a theoretical discussion — it is becoming a board-level business requirement.
My perspective: Many organizations are still approaching AI governance as a documentation exercise instead of an operational discipline. The companies that will succeed with AI over the next five years will be the ones that treat AI governance like cybersecurity — continuous, measurable, risk-based, and integrated directly into business operations. AI risk management is no longer optional; it is becoming the foundation for trustworthy and sustainable AI adoption.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
Sun Tzu for the AI Governance Era: 7 Strategic Rules for InfoSec and Compliance Leaders
Most people treat strategy as a deliverable. A roadmap, a Gantt chart, a board slide with quarterly milestones. Sun Tzu would have laughed. Twenty-five centuries ago he understood what we keep forgetting: strategy isn’t the plan — it’s how you think when the plan stops working. And in cybersecurity, compliance, and AI governance, the plan stops working constantly.
Threat actors don’t read your risk register. Regulators publish new guidance the week after you certify. Generative AI ships features faster than your governance committee can convene. Every static playbook is dying the moment it’s printed.
So let me reframe Sun Tzu’s 7 rules for the people I actually work with — CISOs, compliance officers, AI risk leaders, and the boards trying to steer through all of it.
1. Know your enemy
In war, the enemy is the army across the field. In our world, the “enemy” is plural and shape-shifting: ransomware crews, nation-state operators, insider threats, prompt-injection adversaries, model-extraction attackers, supply-chain compromisers, and increasingly the AI systems your own organization deploys without governance.
Knowing the enemy means real threat intelligence, not a copy-pasted MITRE ATT&CK heatmap. It means red-teaming your AI models for jailbreaks and data leakage. It means watching the EU AI Office, the FTC, and your sector regulator with the same discipline you bring to watching CVEs. The threat surface even includes your auditors and your regulators — not as enemies, but as forces with goals, deadlines, and patterns you must understand if you want to anticipate them rather than be surprised by them.
2. Know yourself
This is where most programs collapse. You can’t defend what you can’t inventory. You can’t certify what you can’t describe. In ISO 27001, this shows up as a broken asset register. In ISO 42001, it’s a missing AI system inventory. In EU AI Act readiness, it’s the inability to honestly classify your systems against Annex III.
Honest self-knowledge means admitting the shadow AI your sales team is already using. It means knowing which controls are operating, which are documented but theatrical, and which exist only on paper. Stage 2 auditors don’t fail organizations because they lack controls — they fail them because the organization didn’t know itself well enough to see the gap before the auditor arrived.
3. Deception — or really, unpredictability
Sun Tzu’s deception principle is widely misread as “lie to the adversary.” In modern terms it means something sharper: don’t be predictable. A predictable defender is a defeated defender.
Predictability in our field looks like patching only on Tuesdays, running the same phishing simulation every quarter, performing identical access reviews on identical schedules, deploying the same detection rules every analyst on LinkedIn just bragged about. Attackers automate against patterns. Mature programs vary their cadence, layer deception technology (honeypots, honeytokens, canary models), and stagger their controls so an adversary who breaks one assumption doesn’t get the whole map. In AI governance, the same principle says: don’t let your model behavior become so deterministic that prompt-injection paths become trivial to chart.
4. Adaptation
The rigid tree breaks; the reed bends. Compliance programs that treat ISO 27001, SOC 2, or ISO 42001 as a “get certified and freeze” exercise snap the moment the standard updates, the business pivots, or a new regulation lands. The EU AI Act’s August 2026 high-risk obligations are not a one-time hurdle. NIST AI RMF will keep evolving. HIPAA enforcement is being reshaped by AI use cases nobody anticipated five years ago.
The adaptive program builds change into its bones: continuous control monitoring, living risk registers, AI inventories that update as deployments happen, and governance committees with the authority to actually change course rather than just observe it. The reed survives because it expects the storm.
5. Timing
Patience creates power. The wrong control at the wrong time is still a failure — even if it’s the technically correct control.
Deploying an AI system before a Conformity Assessment is finished isn’t bravery, it’s regulatory exposure. Announcing a breach without coordinated counsel and forensics burns trust you could have kept. Pushing for SOC 2 Type II before you have six months of evidence wastes the audit. Certifying to ISO 42001 before you’ve operationalized the AIMS turns your certificate into a liability the first time a customer asks a hard question.
Waiting too long is the other failure mode. Organizations dragging their feet on EU AI Act readiness will find themselves competing for the same scarce notified bodies and conformity assessment capacity in 2026, paying a premium for the privilege of being late. Timing is the discipline of moving exactly when the move is decisive — neither earlier nor later.
6. Use strength against weakness
Don’t fight where the adversary is strong. And don’t audit where your control is weakest and call it strategy. Pick the terrain.
For defenders, this means leveraging what you already have. If you’re ISO 27001 certified, the majority of your ISO 42001 control set is already mapped — don’t rebuild from scratch, extend. If you have a mature third-party risk program, AI vendor governance is an extension of it, not a new function. If your detection stack is strong at the identity layer, fight there first and harden endpoints in parallel. For consultancies and internal programs alike, this also means leading with the work where your scar tissue is deepest, not competing on commoditized engagements where price has already won the race.
7. Win without fighting
The highest mastery is preventing the incident, not responding to it gracefully. Sun Tzu’s “winning without fighting” is the entire premise of preventive controls, security-by-design, and governance-by-design.
In InfoSec, it’s the patch that closes the vuln before the exploit hits, the phishing-resistant MFA that retires the credential-theft pathway entirely, the segmentation that means the ransomware can’t move. In compliance, it’s the embedded control that makes the audit boring — because there’s nothing left to find. In AI governance, it’s the model risk assessment done before deployment, the bias testing done before customer harm, the data lineage documented before the regulator asks. The breach you avoid, the fine you never receive, the audit finding that never exists — these are the wins nobody writes a case study about. They are also the most valuable wins you will ever produce.
My perspective
After 16+ years in this work, including the ShareVault ISO 42001 implementation that took us through a Stage 2 audit this year, here’s what I’ve come to believe.
Sun Tzu’s rules survive because they’re not really about war. They’re about navigating systems with intelligent, adaptive opponents under uncertainty — which is exactly what InfoSec, compliance, and AI governance are. Our adversaries are not just attackers. They include regulators, market dynamics, our own organizational inertia, and increasingly the emergent behavior of the AI systems we deploy.
The practitioners who win in this space are not the ones with the thickest binders or the most certifications on the wall. They are the ones who internalize a few things: that programs are living organisms, that honest self-assessment beats sophisticated reporting, that timing matters as much as content, and that the best outcome is usually the incident that never happened and the audit finding that never appeared.
If I had to compress Sun Tzu’s seven rules into one sentence for an AI governance leader stepping into 2026, it would be this:
Build a program that knows what it is, knows what it faces, moves when it should move, and makes most of its victories invisible.
That is strategy. Everything else is just paperwork.
DISC InfoSec helps B2B SaaS and financial services organizations operationalize ISO 27001, ISO 42001, EU AI Act, NIST AI RMF, and HIPAA — with a practitioner’s bias for governance that holds up under audit and under attack.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
Your Shadow AI Inventory Is Wrong. Here’s a Free Way to Fix It.
If I asked your CISO or DPO today, “What’s the complete list of AI tools touching company or customer data?” — what would they hand you?
In most B2B SaaS and financial services orgs I work with, the answer is a stale spreadsheet of the four or five tools that got procurement approval, plus a vague acknowledgement that “people are probably using ChatGPT.” That’s not an AI inventory. That’s wishful thinking with a header row.
And it’s about to become an audit finding.
Why this gap matters now
EU AI Act obligations for general-purpose AI and high-risk systems are arriving in waves through August 2026. ISO 42001 Clause 6.1 expects you to identify AI risks tied to the specific systems in use. HIPAA enforcement around PHI in genAI tools is already here. NIST AI RMF’s GOVERN function presumes you can name what you govern.
Every one of those frameworks has the same prerequisite: a current, defensible inventory of every AI system in scope — including the ones nobody told you about.
Standard discovery tooling misses most of it. DLP doesn’t catch a browser tab. CASB doesn’t see a personal Claude session on a managed device. OAuth audits in Workspace and Entra catch the embedded SaaS AI but skip the web tools entirely. The result: most “AI inventories” are 30–40% of reality, and the missing 60% is exactly where the unreviewed PHI, PII, and source code is flowing.
A practical way to close the gap (free)
I’ve been collaborating with the team at Aguardic on a Shadow AI Discovery tool that I think is genuinely useful for anyone running an AI governance program. It’s free, browser-based, and you don’t need to install anything.
Three inputs:
What you already know. Free-text list of AI tools your team uses — browser, embedded SaaS, dev tools, voice transcribers. Anything you’ve spotted.
Optional: a DNS or proxy log export. Cisco Umbrella, Cloudflare Zero Trust, NextDNS, Pi-hole — the tool has inline export instructions for each. Files are parsed in memory, not stored.
Optional: an OAuth grants export. Google Workspace, Microsoft 365 / Entra ID, Okta, Auth0 — again with step-by-step export guides in the form.
It matches everything against a curated catalog of 100+ AI tools and produces an editable Word report with, per tool: BAA coverage status, framework exposure (HIPAA, EU AI Act, GDPR, ISO 42001, NIST AI RMF, SOC 2, Colorado AI Act, FERPA, PCI DSS), a risk rating tied to the frameworks you selected, and a specific policy recommendation.
Want a professional AI risk assessment you can actually share with leadership or clients?
Contact DISC InfoSec directly to help run the report and deliver it as a DISC InfoSec co-branded assessment — positioned as a polished executive-ready deliverable, not just another vendor-generated brochure.
A great way to start conversations around Shadow AI, AI governance, and enterprise AI risk visibility.
→ https://www.aguardic.com/
My take
Shadow AI isn’t really a tool problem. It’s a governance sequencing problem.
Most organizations I see are trying to write AI acceptable use policies, vendor risk frameworks, and ISO 42001 documentation before they actually know what AI is in use. The policy ends up referencing “approved AI tools” without naming any, the risk register has three line items when it should have thirty, and the internal auditor’s first question — “how did you scope this?” — has no defensible answer.
ISO 42001 Clause 4 (Context) and Annex A.4 (Resources for AI systems) both presume you have an inventory you trust. EU AI Act Article 9 (Risk Management) presumes the same. You cannot classify a high-risk AI system under Annex III if you don’t know the system exists.
Discovery is the first 80% of the work that makes every downstream control function. Skip it, and your governance program is governing a fiction.
If you’ve been putting this off because the manual version is painful — surveying employees, chasing IT for DNS logs, mapping each tool to controls one by one — this is a 10-minute version of that work that gives you something concrete to bring to your next steering committee.
Run it, share the report, and use it as the starting point for the AI risk register you should already have.
If you want help operationalizing what the report surfaces — turning the findings into an ISO 42001 Annex A control set, an EU AI Act classification decision, or a vendor risk workflow — that’s what we do at DISC InfoSec. Reach out.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.
The enterprise AI security problem is no longer theoretical — it is already unfolding inside organizations at a much faster pace than governance teams can control. A recent discussion featuring Slavik Markovich and Rishi Bhargava from Descope highlighted a real-world example that perfectly captures the emerging risks of agentic AI adoption. In the scenario, a salesperson attended an AI workshop, built an autonomous AI agent with access to Gmail and calendar systems, and attempted to secure it using nothing more than a secret URL. There was no authentication, no authorization framework, and no oversight from security or governance teams.
What makes this situation alarming is not the technical simplicity of the mistake — it is how common these behaviors are becoming across enterprises. Employees are increasingly deploying AI agents, copilots, and automation workflows outside traditional governance processes, creating a new wave of shadow AI risks that most organizations are not prepared to manage. In many cases, these systems gain access to sensitive business applications, internal APIs, customer data, and operational workflows without proper security validation or executive visibility.
The larger problem is that most enterprise APIs were never designed for autonomous AI exposure. Traditional APIs assumed predictable software behavior and human-controlled interactions. AI agents fundamentally change that model. They can autonomously make decisions, chain actions together, interact with multiple systems, and execute tasks with varying degrees of unpredictability. This creates a massive governance and identity management challenge that existing security architectures were not built to handle.
One of the most important insights from the discussion is that AI agents require identity governance just like human users — but with far greater complexity. Unlike deterministic applications, AI agents are probabilistic actors. They may behave differently under changing prompts, context windows, external data inputs, or evolving objectives. Even when operating within assigned permissions, their actions may produce unintended consequences that traditional access control systems cannot easily predict or constrain.
This introduces a dangerous gap between innovation and governance. Organizations are racing to deploy AI-enabled productivity tools while security, risk, and compliance programs struggle to establish visibility and control. Many executives still view AI governance as a policy exercise, while the operational reality is that employees are already connecting AI agents directly into enterprise environments with privileged access to sensitive systems and data.
The implications extend far beyond cybersecurity. Poorly governed AI agents can create compliance violations, privacy exposure, intellectual property leakage, inaccurate automated decisions, and reputational damage. In regulated industries, these risks may also trigger legal and regulatory consequences if organizations cannot demonstrate accountability, auditability, and control over autonomous AI actions.
This is why AI governance must evolve beyond traditional security thinking. Organizations need identity-centric AI governance models that include agent authentication, fine-grained authorization, runtime monitoring, behavioral analytics, policy enforcement, human oversight, and continuous auditing of AI actions. AI agents should be treated as privileged digital identities — not as lightweight automation scripts operating outside governance boundaries.
Another major challenge is visibility. Many organizations currently lack the ability to discover where AI agents are deployed, what systems they access, what APIs they interact with, and what decisions they are making autonomously. Without continuous AI discovery and monitoring, security teams may not even realize these risks exist until a data exposure or operational incident occurs.
The rise of agentic AI is forcing enterprises to rethink identity and access management itself. Traditional IAM systems were designed for humans and static machine accounts. AI agents introduce a new category of dynamic, autonomous identities that require adaptive trust models, contextual access controls, and continuous governance throughout the AI lifecycle.
My perspective: The industry is underestimating how quickly AI agents are becoming operational actors inside enterprises. The conversation should no longer focus solely on “AI productivity” but on AI accountability, identity, and control. Organizations that fail to establish AI governance guardrails now may face significant security, compliance, and operational consequences later. The future of AI security will not be defined only by protecting models — it will be defined by governing autonomous AI identities operating across enterprise ecosystems.
DISC InfoSec is an active ISO 42001 implementer and PECB Authorized Training Partner specializing in AI governance for B2B SaaS and financial services organizations.