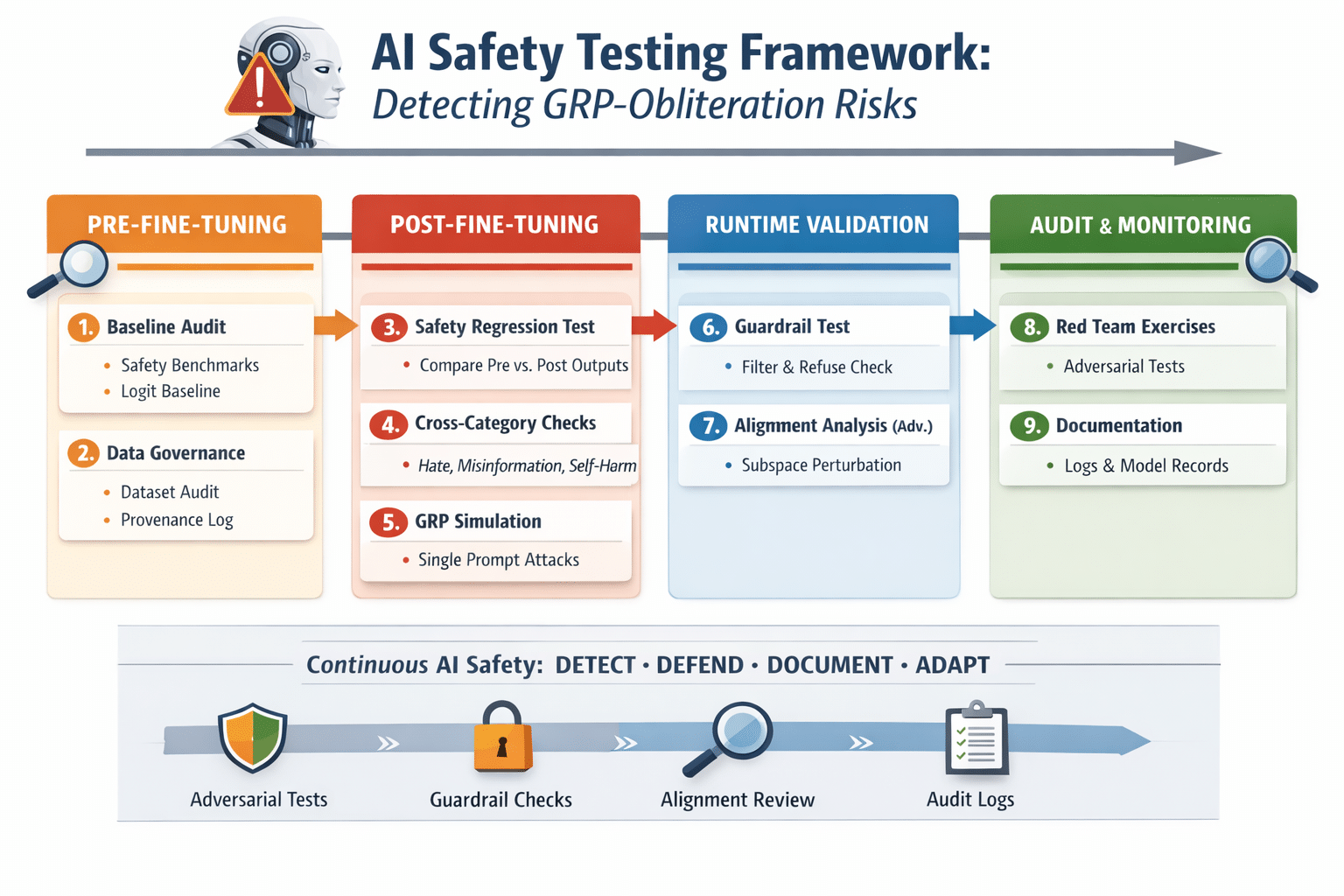
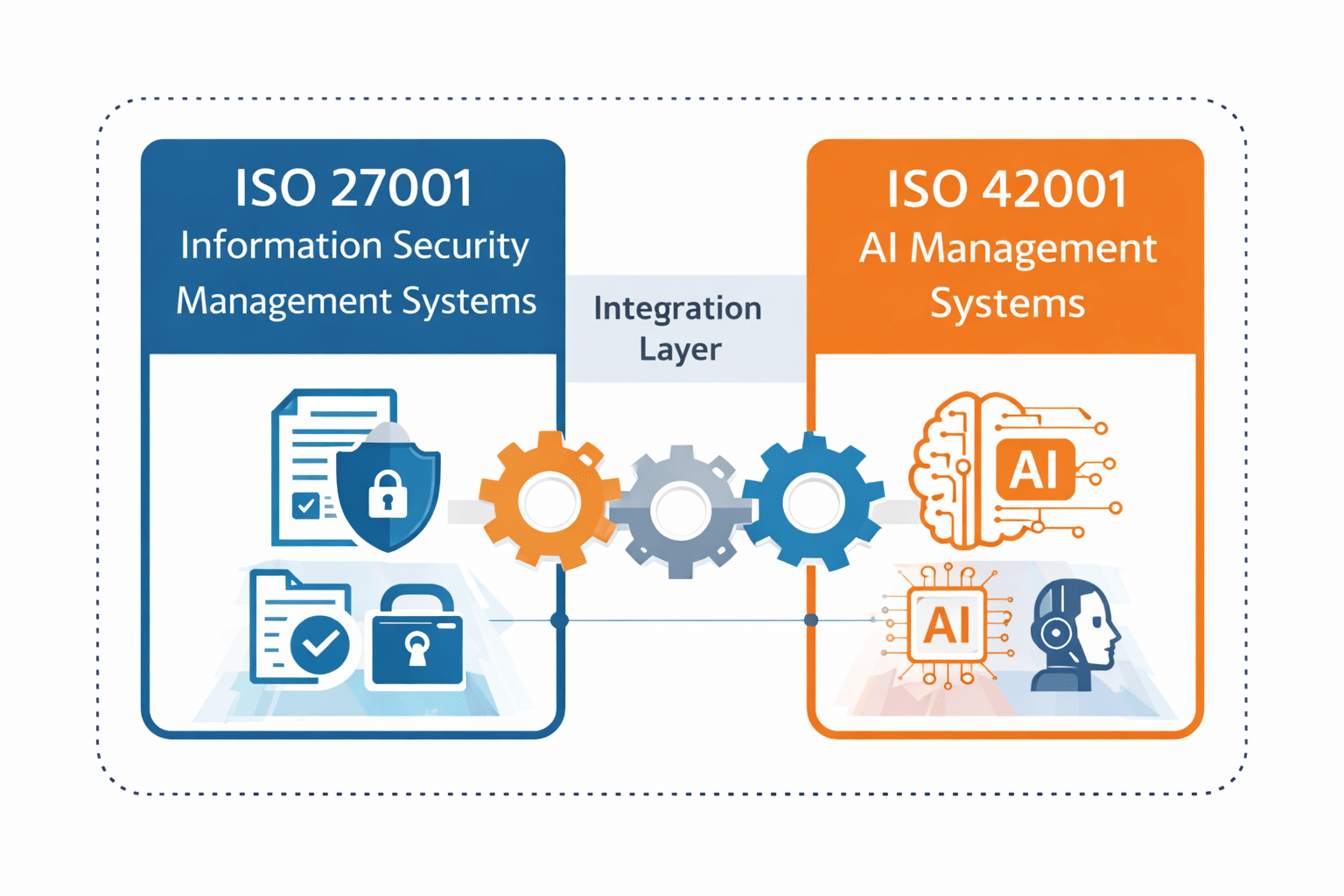
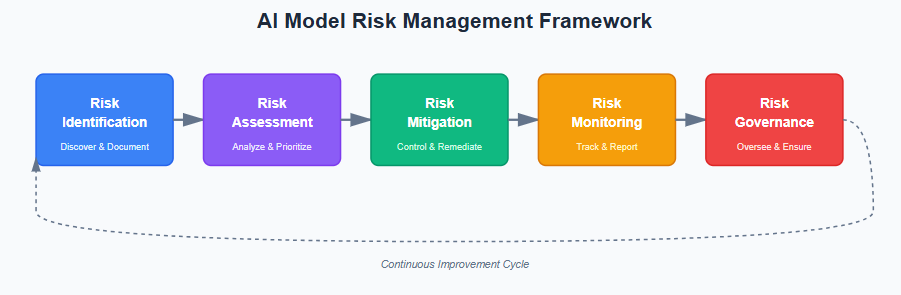
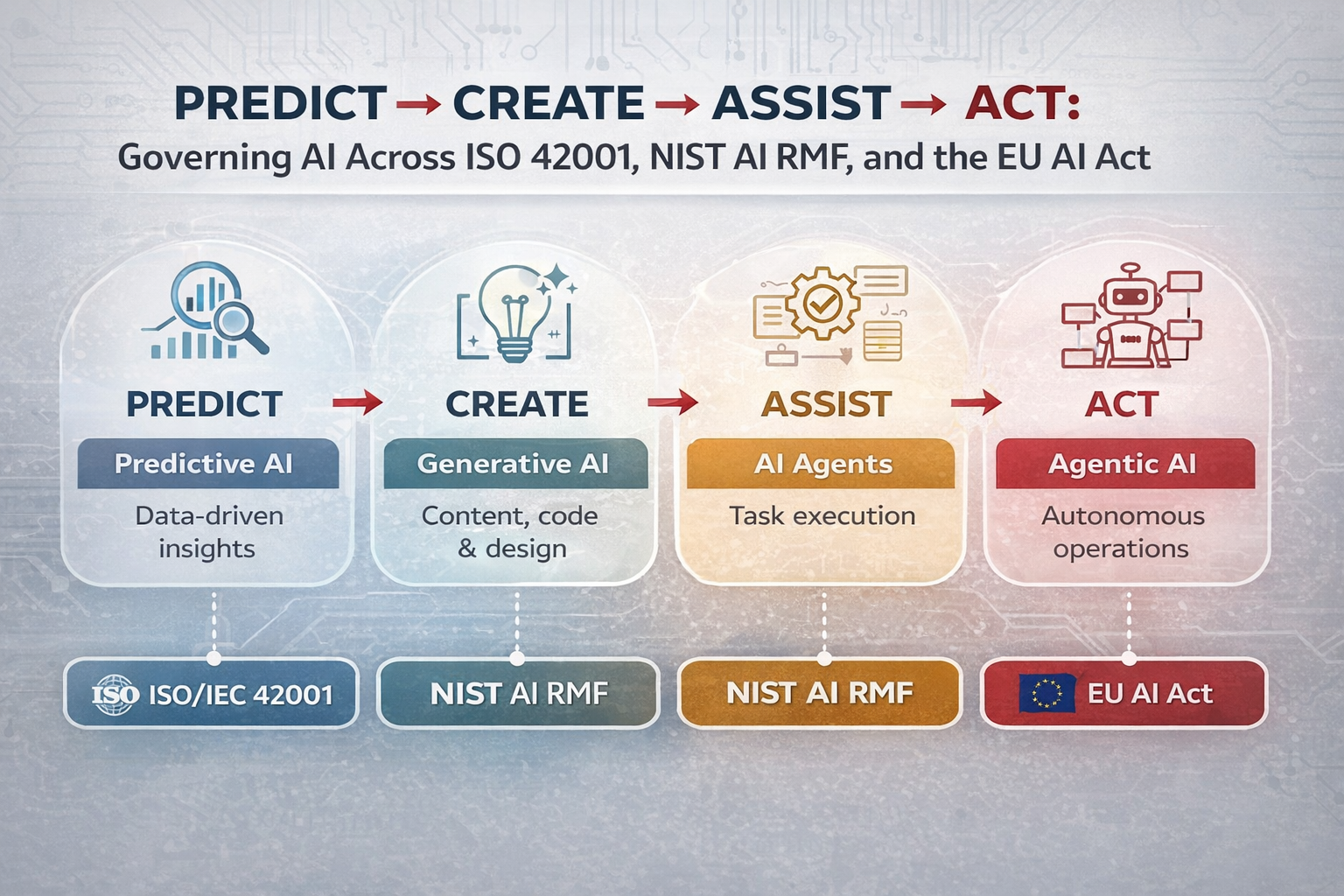
Why Security Controls Are Necessary for Agentic Systems & Agents
Agentic AI systems—systems that can plan, make decisions, and take actions autonomously—introduce a new category of security risk. Unlike traditional software that executes predefined instructions, agents can dynamically decide what actions to take, interact with tools, call APIs, access data sources, and trigger workflows. If these capabilities are not carefully controlled, the system can gain excessive agency, meaning it can act beyond intended boundaries. This could lead to unauthorized data access, unintended transactions, privilege escalation, or operational disruptions. Therefore, organizations must implement strong security measures to ensure that AI agents operate within clearly defined limits, with oversight, accountability, and verification mechanisms.
1. Restrict Agent Capabilities
One of the most important safeguards is limiting what an AI agent is allowed to do. This involves restricting system access, controlling which tools the agent can use, and imposing strict action constraints. Agents should only have access to the minimum resources required to complete their task—following the principle of least privilege. For example, an AI assistant analyzing documents should not have the ability to modify databases or execute system-level commands. Tool usage should also be restricted through allowlists so that the agent cannot invoke unauthorized APIs or services. By enforcing capability boundaries, organizations reduce the risk of misuse, accidental damage, or malicious exploitation.
2. Use Strong Authentication and Authorization
Robust identity and access management is critical for controlling agent behavior. Technologies such as OAuth, multi-factor authentication (2FA), and role-based access control (RBAC) help ensure that only verified users, services, and agents can access sensitive systems. OAuth allows agents to obtain temporary and scoped access tokens rather than permanent credentials, reducing the risk of credential exposure. RBAC ensures that agents only perform actions aligned with their assigned roles, while 2FA strengthens authentication for human operators managing the system. Together, these mechanisms create a layered security model that prevents unauthorized access and limits the impact of compromised credentials.
3. Continuous Monitoring
Because AI agents can operate autonomously and interact with multiple systems, continuous monitoring is essential. Organizations should implement real-time logging, behavioral monitoring, and anomaly detection to track agent activities. Monitoring systems can identify unusual behavior patterns, such as excessive API calls, unexpected data access, or actions outside normal operational boundaries. Security teams can then respond quickly to potential threats by suspending the agent, revoking permissions, or investigating suspicious activity. Continuous monitoring also provides an audit trail that supports incident response and regulatory compliance.
4. Regular Audits and Updates
Agentic systems require ongoing evaluation to ensure that their security posture remains effective. Regular security audits help verify that access controls, permissions, and operational boundaries are functioning as intended. Organizations should also update models, tools, and system configurations to address newly discovered vulnerabilities or evolving threats. This includes reviewing agent capabilities, validating governance policies, and ensuring compliance with relevant frameworks such as AI governance standards and cybersecurity best practices. Periodic reviews help maintain control over autonomous systems as they evolve and integrate with new technologies.
Perspective
In my view, the rise of agentic AI fundamentally changes the security model for software systems. Traditional applications follow predictable execution paths, but AI agents introduce adaptive behavior that can interact with environments in unforeseen ways. This means security must shift from simple perimeter defenses to governance over capabilities, identity, and behavior.
Beyond the measures listed above, organizations should also consider human-in-the-loop approval for critical actions, policy-based guardrails, sandboxed execution environments, and strong prompt and tool validation. Agentic AI is powerful, but without structured controls it can quickly become a high-risk automation layer inside enterprise infrastructure.
The organizations that succeed with agentic AI will be those that treat AI autonomy as a privileged capability that must be governed, monitored, and continuously validated—just like any other critical security control.
Get Your Free AI Governance Readiness Assessment – Is your organization ready for ISO 42001, EU AI Act, and emerging AI regulations?
AI Governance Gap Assessment tool
- 15 questions
- Instant maturity score
- Detailed PDF report
- Top 3 priority gaps
Click below to open an AI Governance Gap Assessment in your browser or click the image to start assessment.
ai_governance_assessment-v1.5Download
Built by AI governance experts. Used by compliance leaders.

InfoSec services | InfoSec books | Follow our blog | DISC llc is listed on The vCISO Directory | ISO 27k Chat bot | Comprehensive vCISO Services | ISMS Services | AIMS Services | Security Risk Assessment Services | Mergers and Acquisition Security
At DISC InfoSec, we help organizations navigate this landscape by aligning AI risk management, governance, security, and compliance into a single, practical roadmap. Whether you are experimenting with AI or deploying it at scale, we help you choose and operationalize the right frameworks to reduce risk and build trust. Learn more at DISC InfoSec.
- When AI Hacks Faster Than Humans: The Coming Collapse of Traditional Cybersecurity Value
- SOC 2 Isn’t Enough: Moving Beyond Compliance Theater to Real Risk Management
- When AI Becomes the Attack Surface: Lessons from the McKinsey Lilli Incident
- Why Every Company Needs a CISO (or at Least vCISO-Level Leadership)
- How ISO 27001 Lead Auditors Should Evaluate AI Risks in an ISMS