
🔹 1. Unacceptable Risk (Prohibited AI)
These are AI practices banned outright because they pose a clear threat to safety, rights, or democracy.
Examples:
- Social scoring by governments (like assigning citizens a “trust score”).
- Real-time biometric identification in public spaces for mass surveillance (with narrow exceptions like serious crime).
- Manipulative AI that exploits vulnerabilities (e.g., toys with voice assistants that encourage dangerous behavior in kids).
👉 If your system falls here → cannot be marketed or used in the EU.
🔹 2. High Risk
These are AI systems with significant impact on people’s rights, safety, or livelihoods. They are allowed but subject to strict compliance (risk management, testing, transparency, human oversight, etc.).
Examples:
- AI in recruitment (CV screening, job interview analysis).
- Credit scoring or AI used for approving loans.
- Medical AI (diagnosis, treatment recommendations).
- AI in critical infrastructure (electricity grid management, transport safety systems).
- AI in education (grading, admissions decisions).
👉 If your system is high-risk → must undergo conformity assessment and registration before use.
🔹 3. Limited Risk
These require transparency obligations, but not full compliance like high-risk systems.
Examples:
- Chatbots (users must know they’re talking to AI, not a human).
- AI systems generating deepfakes (must disclose synthetic nature unless for law enforcement/artistic/expressive purposes).
- Emotion recognition systems in non-high-risk contexts.
👉 If limited risk → inform users clearly, but lighter obligations.
🔹 4. Minimal or No Risk
The majority of AI applications fall here. They’re largely unregulated beyond general EU laws.
Examples:
- Spam filters.
- AI-powered video games.
- Recommendation systems for e-commerce or music streaming.
- AI-driven email autocomplete.
👉 If minimal/no risk → free use with no extra requirements.
⚖️ Rule of Thumb for Classification:
- If it manipulates or surveils → often unacceptable risk.
- If it affects health, jobs, education, finance, safety, or fundamental rights → high risk.
- If it interacts with humans but without major consequences → limited risk.
- If it’s just convenience or productivity-related → minimal/no risk.
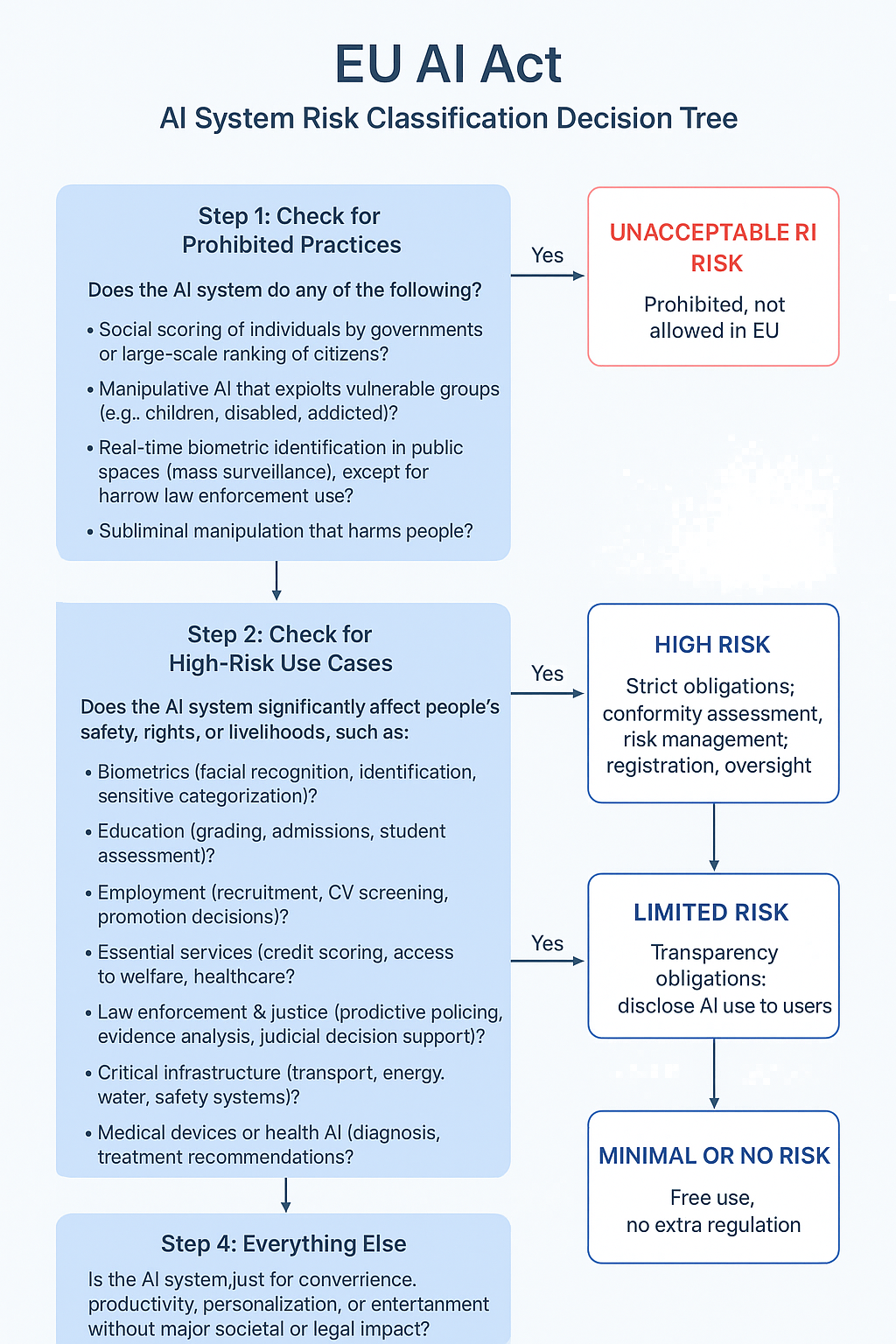
A decision tree you can use to classify any AI system under the EU AI Act risk framework:
🧭 EU AI Act AI System Risk Classification Decision Tree
Step 1: Check for Prohibited Practices
👉 Does the AI system do any of the following?
- Social scoring of individuals by governments or large-scale ranking of citizens?
- Manipulative AI that exploits vulnerable groups (e.g., children, disabled, addicted)?
- Real-time biometric identification in public spaces (mass surveillance), except for narrow law enforcement use?
- Subliminal manipulation that harms people?
✅ Yes → UNACCEPTABLE RISK (Prohibited, not allowed in EU).
❌ No → go to Step 2.
Step 2: Check for High-Risk Use Cases
👉 Does the AI system significantly affect people’s safety, rights, or livelihoods, such as:
- Biometrics (facial recognition, identification, sensitive categorization)?
- Education (grading, admissions, student assessment)?
- Employment (recruitment, CV screening, promotion decisions)?
- Essential services (credit scoring, access to welfare, healthcare)?
- Law enforcement & justice (predictive policing, evidence analysis, judicial decision support)?
- Critical infrastructure (transport, energy, water, safety systems)?
- Medical devices or health AI (diagnosis, treatment recommendations)?
✅ Yes → HIGH RISK (Strict obligations: conformity assessment, risk management, registration, oversight).
❌ No → go to Step 3.
Step 3: Check for Transparency Requirements (Limited Risk)
👉 Does the AI system:
- Interact with humans in a way that users might think they are talking to a human (e.g., chatbot, voice assistant)?
- Generate or manipulate content that could be mistaken for real (e.g., deepfakes, synthetic media)?
- Use emotion recognition or biometric categorization outside high-risk cases?
✅ Yes → LIMITED RISK (Transparency obligations: disclose AI use to users).
❌ No → go to Step 4.
Step 4: Everything Else
👉 Is the AI system just for convenience, productivity, personalization, or entertainment without major societal or legal impact?
✅ Yes → MINIMAL or NO RISK (Free use, no extra regulation).
⚖️ Quick Classification Examples:
- Social scoring AI → ❌ Unacceptable Risk
- AI for medical diagnosis → 🚨 High Risk
- AI chatbot for customer service → ⚠️ Limited Risk
- Spam filter / recommender system → ✅ Minimal Risk
From Compliance to Confidence: How DISC LLC Delivers Strategic Cybersecurity Services That Scale
Expertise-in-Virtual-CISO-vCISO-Services-2Download
Secure Your Business. Simplify Compliance. Gain Peace of Mind
InfoSec services | InfoSec books | Follow our blog | DISC llc is listed on The vCISO Directory | ISO 27k Chat bot | Comprehensive vCISO Services | ISMS Services | Security Risk Assessment Services | Mergers and Acquisition Security




